
Les « Captcha », ces petits tests d’identification prouvant qu’un internaute est bien humain et non un robot, ont bien failli coûter une « class action » à Google. Le 3 février, la justice américaine a rejeté la plainte d’une femme qui souhaitait attaquer Google dans un recours collectif, accusant l’entreprise de « tirer profit » de « la main d’œuvre gratuite » que représentent les internautes.
En effet, en remplissant les Captcha utilisés par Google, les internautes ne se contentent pas de prouver leur humanité : ils participent, souvent sans le savoir, à des projets plus larges. Dans le cas de cette plainte, était visé reCAPTCHA, ce test contribuait à numériser des livres pour l’immense bibliothèque numérique de Google.
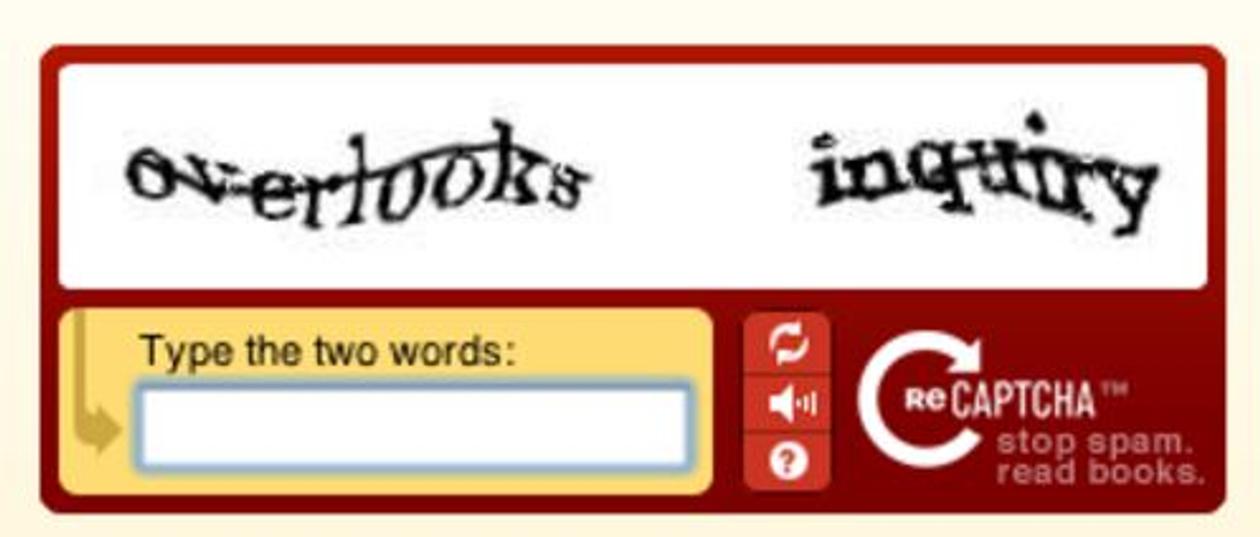
Ce Captcha ressemble à première vue à tous les autres : des mots déformés, illisibles pour une machine, mais pas par un humain. Si l’internaute est capable de les déchiffrer, c’est donc qu’il ne s’agit pas d’un robot risquant de « spammer » (envoyer des messages indésirables) le site sur lequel le captcha est affiché.
Mais dans le cas de reCAPTCHA, seul le premier mot sert en réalité cet objectif. Le deuxième est en fait issu d’un des millions de livres ou journaux numérisés par Google. Les logiciels de reconnaissance de caractères ayant leurs limites, certains termes n’ont pas pu être déchiffrés automatiquement. Google se sert donc des internautes pour le faire « à la main » ; ce dont il ne s’est jamais caché. « La plaignante n’a pas donné d’éléments permettant de suggérer de façon plausible que les quelques secondes nécessaires pour taper un second mot mériteraient, pour des consommateurs raisonnables, de recevoir une compensation », a estimé la justice américaine.
« Rentabiliser » le temps des utilisateurs
Une péripétie de plus dans la courte histoire des Captcha, marquée par l’inventivité de leurs développeurs pour les faire évoluer, afin de contrer les progrès des nouveaux programmes cherchant à les tromper.
Le terme « captcha » est né au début des années 2000, dans les locaux de l’université Carnegie-Mellon à Pittsburgh, en Pennsylvanie. Sa signification : Completely Automated Public Turing test to tell Computers and Humans Apart, soit « test de Turing complètement automatique et public pour distinguer les ordinateurs des humains ». Ce nom fait référence au célèbre test censé déterminer si un logiciel est assez intelligent pour se faire passer pour un humain. Le Captcha fait l’inverse : vérifier que l’internaute est bien humain en le forçant à se montrer plus intelligent que la machine, incapable de déchiffrer certaines images.
500 000 heures sont consacrées chaque jour à déchiffrer des Captcha.
Si au départ, la plupart des Captcha se contentaient d’afficher l’image d’un mot déformé, l’équipe de l’université Carnegie-Mellon décide d’aller plus loin. En 2006, le groupe de recherche travaillant sur le sujet estime que 200 millions de Captcha sont déchiffrés chaque jour. Si l’on considère que cela prend dix secondes par personne, cinq cent mille heures sont ainsi, chaque jour, consacrées à cette tâche. « On s’est donc demandé “pouvons-nous faire quelque chose de ce temps ?” », explique Luis von Ahn, à la tête de cette équipe, au New York Times. C’est ainsi que naît en 2007 l’idée de numériser des livres en utilisant reCAPTCHA, société rachetée par Google en 2009.
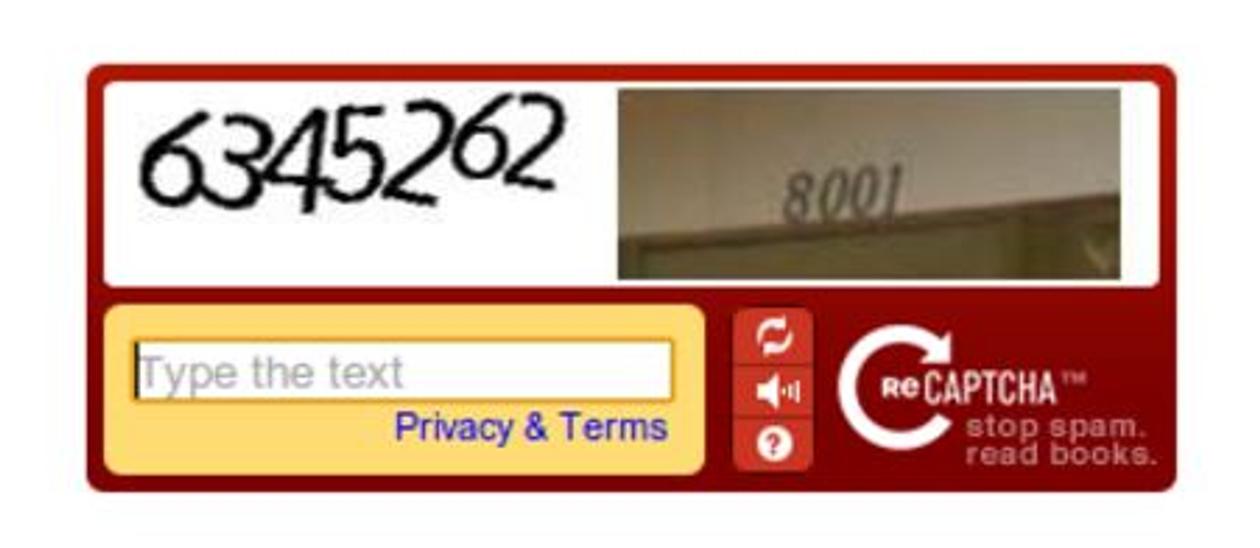
Ce principe sera adapté plus tard, en 2012, à Google Street View : l’internaute se voit proposer de déchiffrer les textes photographiés dans la rue, comme les panneaux routiers ou les numéros de maison. Une tâche là aussi complexe pour une machine, mais facile pour un humain. Objectif, là encore, profiter de la masse des internautes et de leur temps pour enrichir l’outil de Google.
Critiques et parodies
Si les Captcha de Google, que n’importe quel site peut adopter, font partie des plus utilisés du Web, de nombreuses déclinaisons sont inventées, comme le Captcha vidéo, ou le Captcha sous forme de question : « Quel est le résultat de l’addition 5 plus 3 ? », « quelle est la couleur du cheval blanc d’Henri IV ? » La popularité du Captcha donne aussi lieu à des parodies, comme le Metal Captcha, qui consiste à déchiffrer des noms de groupes de musique métal.

D’autres détournent le Captcha à des fins plus sérieuses, comme l’association Civil Rights Defender, qui vérifie l’humanité de l’internaute en faisant appel à ses émotions. « Le vice-ministre de la défense d’Albanie, Ekrem Spahiu, pense que les gays devraient être “frappés avec un bâton”. Comment vous sentez-vous après ça ? » L’utilisateur peut répondre : « Très mal », « glorieux », « assez joyeux ». S’il choisit la première réponse, le Captcha est validé : « Vous êtes humain. »

Mais malgré leur succès, les Captcha de tous types commencent à montrer leurs limites. Les progrès de l’intelligence artificielle mettent au point des programmes de plus en plus à même de déchiffrer les images de mots déformés. En réponse, celles-ci deviennent de plus en plus complexes, au point de devenir parfois illisibles… pour les humains.
Qui plus est, certaines voix commencent à s’élever contre la généralisation des Captcha, qui posent problème pour « les utilisateurs aveugles, malvoyants ou bien dyslexiques », soulignait dès 2005 dans un rapport le World Wide Web Consortium (W3C), l’organisme chargé de fixer les standards du Web. « Ces systèmes de vérification rendent impossible, pour certains utilisateurs handicapés, de créer des comptes, d’écrire des commentaires ou de faire des achats sur ces sites ; ce qui signifie que les Captcha échouent à reconnaître les utilisateurs handicapés comme humains. »
Pour remédier à ce problème, reCAPTCHA incorpore un Captcha sonore pour les internautes qui le souhaitent, dans lequel une voix récite une suite de chiffres à retranscrire.

Des Captcha pour… améliorer l’intelligence artificielle
Néanmoins, avec les progrès de la reconnaissance vocale, bien illustrée par les assistants vocaux Siri et Cortana, certains programmes réussissent là aussi à tromper le Captcha. Il faut donc inventer de nouveaux systèmes, proposant des problèmes simples pour l’humain, mais encore non résolus par l’intelligence artificielle. Comme la reconnaissance d’images. Si la reconnaissance de caractères dans des images a rendu quasi obsolète les premiers Captcha, les machines ont encore du mal à identifier les objets présents sur une photo.
C’est pourquoi le développeur Oli Warner a inventé, en 2006, KittenAuth. Pour distinguer les humains des robots, il propose neuf images d’animaux et demande aux internautes de cliquer sur celles qui représentent un chat.

Google, de son côté, a complètement réinventé le Captcha à la fin de 2014, reconnaissant dans un billet de blog que « l’intelligence artificielle aujourd’hui [pouvait] résoudre même la variante la plus compliquée de texte déformé avec une exactitude de 99,8 % ». Son nouvel outil, baptisé « No CAPTCHA reCAPTCHA », nécessite tout simplement… de cocher une case. S’il est capable de distinguer la machine de l’humain, c’est que ce dernier ne cochera pas la case de la même manière qu’un robot. En analysant, par exemple, le temps de réaction ou le mouvement de la souris de l’internaute, ce Captcha est capable de « deviner » s’il est bien humain.

Néanmoins, en cas de doute, un test supplémentaire est demandé à l’internaute. Et celui-ci ressemble fortement à celui de KittenAuth, puisqu’il demande à l’internaute d’identifier des images ressemblant à la première proposée. Cette version s’affiche par défaut sur mobile, où l’analyse du « clic » est moins pertinente.

En plus de tromper les programmes les plus intelligents, ce système permet, une fois encore, d’utiliser la masse des internautes pour faire avancer les projets de Google. Cette fois, les internautes participent à un programme de reconnaissance d’images – un des grands défis actuels de l’intelligence artificielle. En labellisant sans s’en rendre compte des millions d’images, ils contribuent à une gigantesque base de données qui « nourrit » des programmes, afin qu’ils apprennent, par eux-mêmes, à identifier le contenu des photos.
En clair, ce Captcha sert à améliorer les programmes de reconnaissance d’image… qui seront ainsi capables de tromper ce même Captcha. Bref, un autosabotage. En attendant qu’un autre système soit inventé pour leur barrer la route – et il serait temps de s’y mettre, tant les progrès en la matière sont importants.
Néanmoins, il se pourrait que toutes ces innovations ne puissent rien contre l’ennemi le plus puissant auquel doivent faire face les Captcha, les humains eux-mêmes. Depuis des années, des entreprises font appel à des humains, vivant dans des pays où la main-d’œuvre est bon marché, pour déchiffrer des Captcha à la chaîne. Et envahir le Web de spams.