



|
Listen to this story
|
Google researchers have introduced a method for scaling Transformer-based large language models (LLMs) to handle infinitely long inputs with bounded memory and computation.
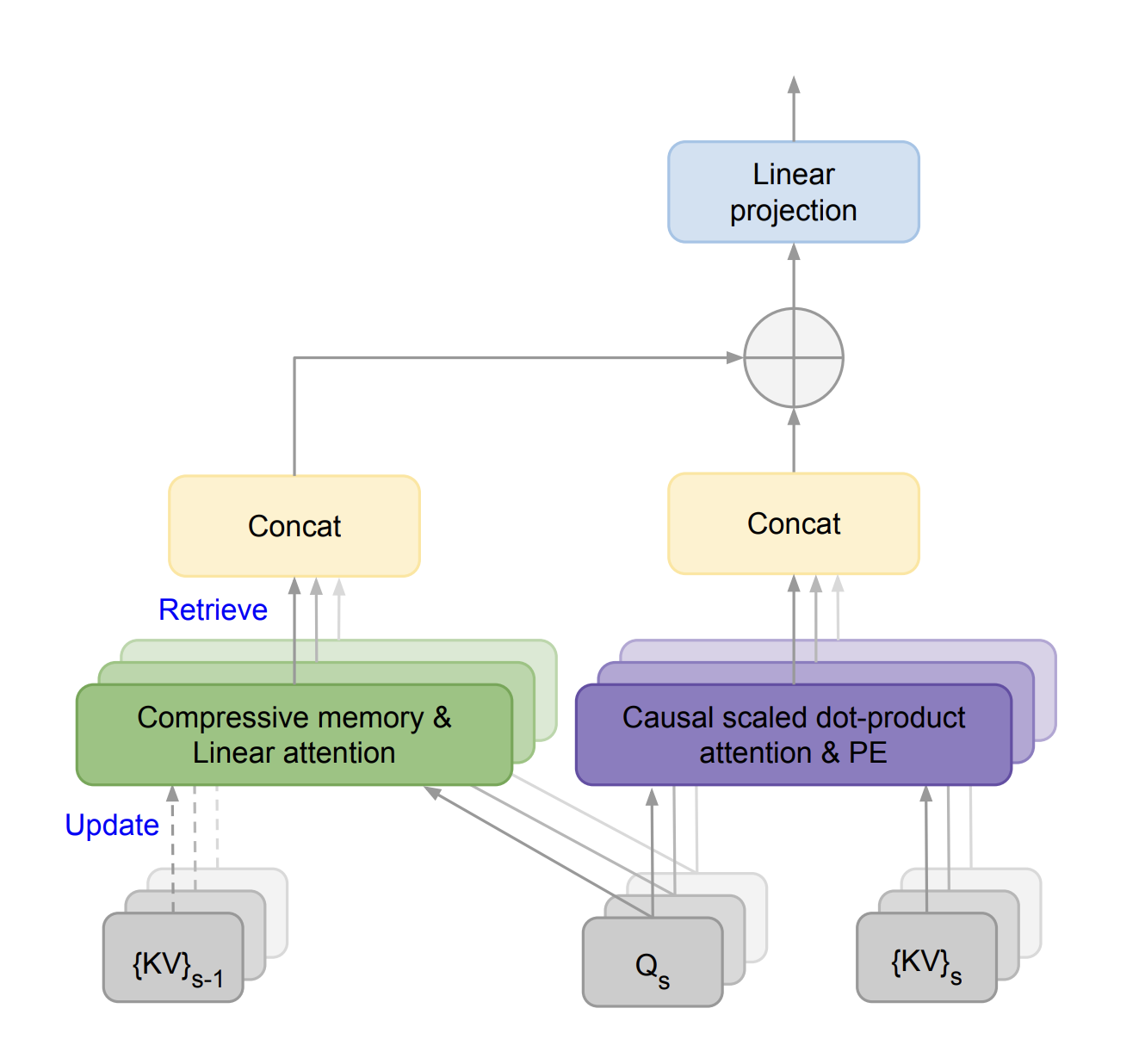
The paper titled Leave No Context Behind devises the approach, known as Infini-attention which incorporates compressive memory into the vanilla attention mechanism and combines masked local attention and long-term linear attention mechanisms in a single Transformer block.
This modification to the Transformer attention layer supports continual pre-training and fine-tuning, facilitating the natural extension of existing LLMs to process infinitely long contexts.
Infini-attention reuses key, value, and query states from standard attention computations for long-term memory consolidation and retrieval. Instead of discarding old key-value (KV) states, the approach stores them in compressive memory and retrieves values using attention query states for processing subsequent sequences. The final contextual output is computed by combining long-term memory-retrieved values with local attention contexts.
Experimental results demonstrate that this approach surpasses baseline models on long-context language modelling benchmarks, achieving a 114x comprehension ratio in terms of memory size.
The model improves perplexity when trained with 100K sequence length. A 1B LLM scales naturally to 1M sequence length, successfully completing the passkey retrieval task when equipped with Infini-attention.
The researchers demonstrated the approach’s effectiveness using long-context language modelling benchmarks, including 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. The method maintains minimal bounded memory parameters and allows for fast streaming inference for LLMs.
The contributions of this work include:
- Infini-attention, which combines long-term compressive memory and local causal attention to efficiently model both long- and short-range contextual dependencies.
- Minimal changes to the standard scaled dot-product attention, allowing for plug-and-play continual pre-training and long-context adaptation.
- Enabling Transformer LLMs to process extremely long inputs in a streaming fashion with bounded memory and compute resources.
Infini-Transformer is compared with Transformer-XL, showing that Infini-Transformer operates on sequences of segments, computing standard causal dot-product attention context within each segment.
Unlike Transformer-XL, Infini-Transformers reuse the KV attention states of previous segments to maintain the entire context history with compressive memory, achieving efficient memory and computation usage.
The conclusion of the study emphasises the importance of an effective memory system for comprehending long contexts with LLMs, reasoning, planning, continual adaptation, and learning. The work integrates a compressive memory module into the vanilla dot-product attention layer, enabling LLMs to process infinitely long contexts with bounded memory and computation resources.
The approach scales naturally to handle million-length input sequences and outperforms baselines on long-context language modelling benchmarks and book summarization tasks. The 1B model, fine-tuned on up to 5K sequence length passkey instances, successfully solved the 1M length problem.














































































