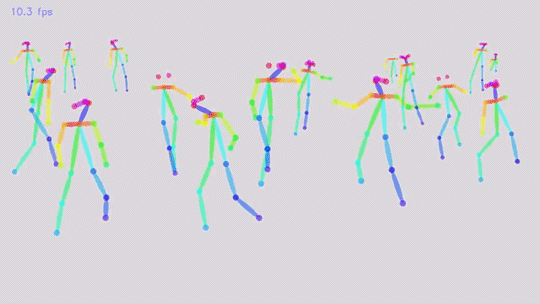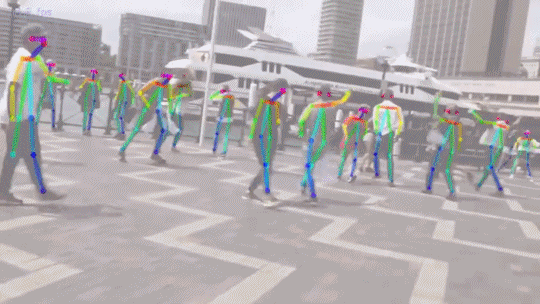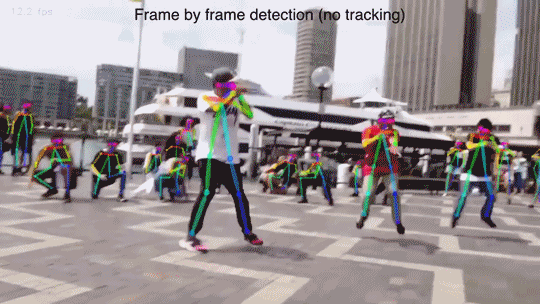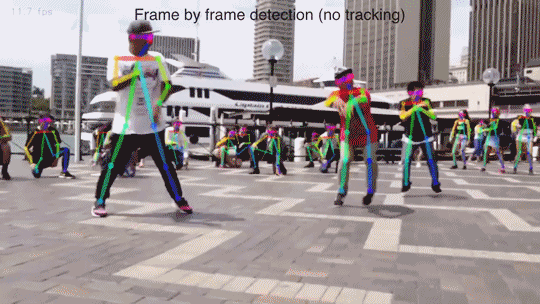
The Panoptic Studio is a new body scanner created by researchers at Carnegie Mellon University that will be used to understand body language in real situations. The scanner, which looks like something Doc Brown would stick Marty in to prevent him from committing fratricide, creates hundreds of videos of participants inside the massive dome interacting, talking, and arguing. The team has even released code to help programmers understand body positions in real time.
The dome contains 480 VGA cameras and 31 HD cameras as well as 10 Kinect sensors. It can create wireframe models of participants inside the dome. Why? To show computers what we are thinking.

“We communicate almost as much with the movement of our bodies as we do with our voice,” said associate professor Yaser Sheikh. “But computers are more or less blind to it.”
In the video below the researchers scanned a group haggling over an object. The computer can look at the various hand and head positions and, potentially, the verbal communication, and begin to understand when two people are angry, happy, or argumentative. It will also let the computer recognize poses including pointing which means you can point to an object and the system will know what you’re talking about.
Interestingly the system can also be used to help patients with autism and dyslexia by decoding their actions in real time. Finally a system like this can be used in sports by scanning multiple participants on a playing field and see where every player was at any one time.
From the release:
The Panopticon isn’t exactly ready for using at the Super Bowl or your local Denny’s but it looks to be a solid enough solution to tell what a few people are doing based on various point clouds of their appendages and actions. They’ve even been able to tell when you might be flicking somebody off.
“A single shot gives you 500 views of a person’s hand, plus it automatically annotates the hand position,” said researcher Hanbyul Joo. “Hands are too small to be annotated by most of our cameras, however, so for this study we used just 31 high-definition cameras, but still were able to build a massive data set.”