 In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Mastering Sketching: Adversarial Augmentation for Structured Prediction
This paper presents an integral framework for training sketch simplification networks that convert challenging rough sketches into clean line drawings. The approach augments a simplification network with a discriminator network, training both networks jointly so that the discriminator network discerns whether a line drawing is a real training data or the output of the simplification network, which in turn tries to fool it.

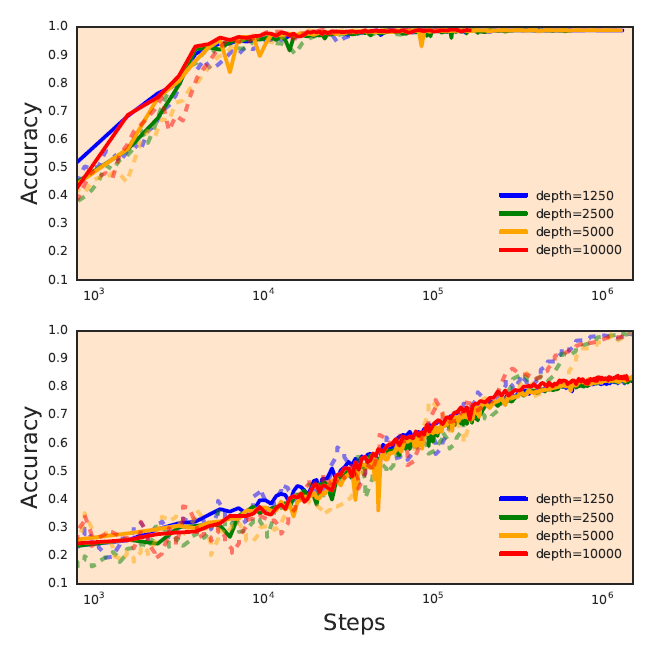
In recent years, state-of-the-art methods in computer vision have utilized increasingly deep convolutional neural network architectures (CNNs), with some of the most successful models employing hundreds or even thousands of layers. A variety of pathologies such as vanishing/exploding gradients make training such deep networks challenging. While residual connections and batch normalization do enable training at these depths, it has remained unclear whether such specialized architecture designs are truly necessary to train deep CNNs. This paper demonstrates that it is possible to train vanilla CNNs with ten thousand layers or more simply by using an appropriate initialization scheme. The authors derive this initialization scheme theoretically by developing a mean field theory for signal propagation and by characterizing the conditions for dynamical isometry, the equilibration of singular values of the input-output Jacobian matrix.
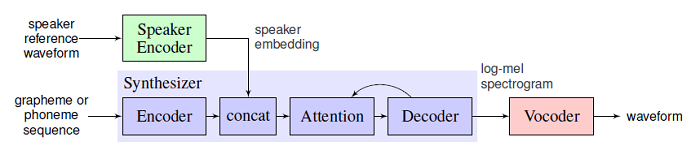
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training.
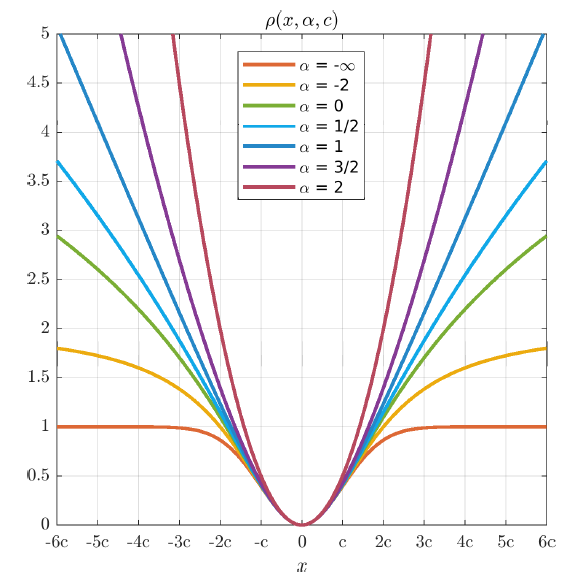
A More General Robust Loss Function
 This paper presents a two-parameter loss function which can be viewed as a generalization of many popular loss functions used in robust statistics: the Cauchy/Lorentzian, Geman-McClure, Welsch/Leclerc, and generalized Charbonnier loss functions (and by transitivity the L2, L1, L1-L2, and pseudo-Huber/Charbonnier loss functions). If this penalty is viewed as a negative log-likelihood, it yields a general probability distribution that includes normal and Cauchy distributions as special cases. The author describe and visualize this loss and its corresponding distribution, and document several of their useful properties.
This paper presents a two-parameter loss function which can be viewed as a generalization of many popular loss functions used in robust statistics: the Cauchy/Lorentzian, Geman-McClure, Welsch/Leclerc, and generalized Charbonnier loss functions (and by transitivity the L2, L1, L1-L2, and pseudo-Huber/Charbonnier loss functions). If this penalty is viewed as a negative log-likelihood, it yields a general probability distribution that includes normal and Cauchy distributions as special cases. The author describe and visualize this loss and its corresponding distribution, and document several of their useful properties.
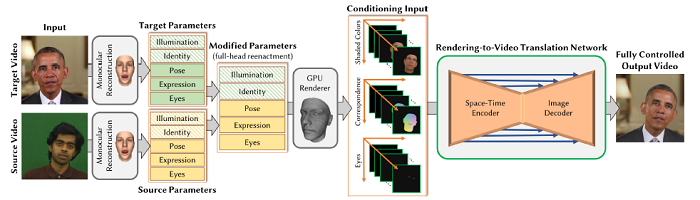
This paper presents a novel approach that enables photo-realistic re-animation of portrait videos using only an input video. In contrast to existing approaches that are restricted to manipulations of facial expressions only, this is the first approach to transfer the full 3D head position, head rotation, face expression, eye gaze, and eye blinking from a source actor to a portrait video of a target actor. The core of the approach is a generative neural network with a novel space-time architecture.
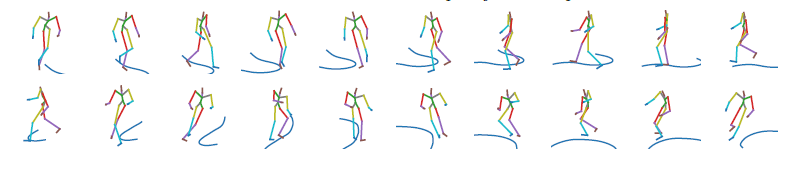
QuaterNet: A Quaternion-based Recurrent Model for Human Motion
Deep learning for predicting or generating 3D human pose sequences is an active research area. Previous work regresses either joint rotations or joint positions. The former strategy is prone to error accumulation along the kinematic chain, as well as discontinuities when using Euler angle or exponential map parameterizations. The latter requires re-projection onto skeleton constraints to avoid bone stretching and invalid configurations. This work addresses both limitations. The proposed recurrent network, QuaterNet, represents rotations with quaternions and the loss function performs forward kinematics on a skeleton to penalize absolute position errors instead of angle errors.
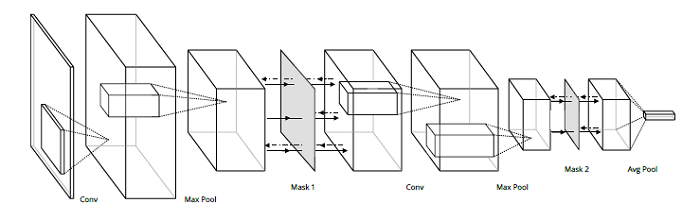
 Backdrop: Stochastic Backpropagation
Backdrop: Stochastic Backpropagation
This paper introduces backdrop, a flexible and simple-to-implement method, intuitively described as dropout acting only along the backpropagation pipeline. Backdrop is implemented via one or more masking layers which are inserted at specific points along the network. Each backdrop masking layer acts as the identity in the forward pass, but randomly masks parts of the backward gradient propagation. Intuitively, inserting a backdrop layer after any convolutional layer leads to stochastic gradients corresponding to features of that scale. Therefore, backdrop is well suited for problems in which the data have a multi-scale, hierarchical structure.
Relational Deep Reinforcement Learning
This paper introduces an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. The results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance.

Sign up for the free insideBIGDATA newsletter.



Speak Your Mind