We take photographs as a way to freeze moments in time and to capture the details that get blurred by our unreliable memories. There is little room for interpretation, and this is kind of the whole point.
[Dan Macnish]’s latest project, Draw This, turns reality into absurdity. It’s a Raspberry Pi-based instant camera that trades whatever passed in front of the lens for a cartoon version of same. Draw This uses neural networks to ID the objects in the frame, and then draws upon thousands of images from Google’s Quick, Draw! dataset to provide a loose interpretation via thermal printer. Seems to us like the perfect camera to take to DEFCON (or any other part of Las Vegas).
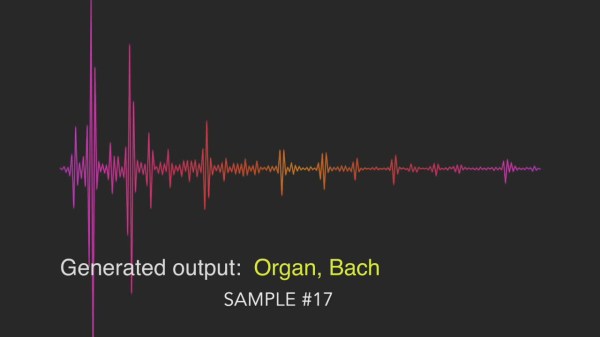
The inspiration for it came from the human ability to hear music played by any instrument and to then be able to whistle or hum it, thereby translating it from one instrument to another. This is something computers have had trouble doing well, until now. The researchers fed their translator a string quartet playing Haydn and had it translate the music to a chorus and orchestra singing and playing in the style of Bach. They’ve even fed it someone whistling the theme from Indiana Jones and had it translate the tune to a symphony in the style of Mozart.
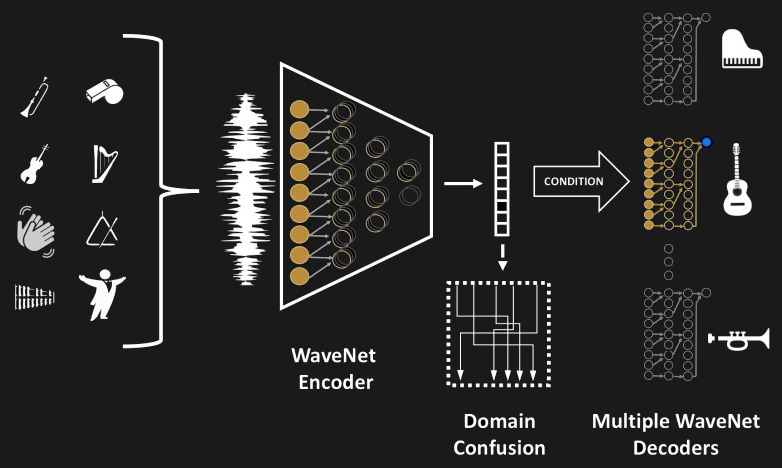
Shown here is the architecture of their network. Note that all the different music is fed into the same encoder network but each instrument which that music can be translated into has its own decoder network. It was implemented in PyTorch and trained using eight Tesla V100 GPUs over a total of six days. Efforts were made during training to ensure that the encoder extracted high-level semantic features from the music fed into it rather than just memorizing the music. More details can be found in their paper.
So if you want to hear how an electric guitar played in the style of Metallica might have been translated to the piano by Beethoven then listen to the samples in the video below.
This past semester I added research to my already full schedule of math and engineering classes, as any masochistic student eagerly would. Packed schedule aside, how do you pass up the chance to work on implementing 360° virtual teleportation to anywhere in the world, in real-time. Yes, it is indeed the same concept as the cult worshipped Star Trek transporter, minus the ability to physically be at the location. Perhaps we can add a, “beam me up, Scotty” command when shutting down.
The research lab I was working with is the Laboratory for Immersive CommunicatiON (LION). It’s funded by NSF, Microsoft, and Adobe and has been on the pursuit of VR teleportation for some time now. There’s a lot of cool technologies at work here, like drones which are used as location collection devices. A network of drones will survey landscape anywhere in the world and build the collection assets needed for recreating it in VR. Okay, so a swarm of drones might seem a little intimidating at first, but when has emerging technology not?
In European medieval folklore, a practitioner of magic may call for assistance from a familiar spirit who takes an animal form disguise. [Alex Glow] is our modern-day Merlin who invoked the magical incantations of 3D printing, Arduino, and Raspberry Pi to summon her familiar Archimedes: The AI Robot Owl.
The key attraction in this build is Google’s AIY Vision kit. Specifically the vision processing unit that tremendously accelerates image classification tasks running on an attached Raspberry Pi Zero W. It no longer consumes several seconds to analyze each image, classification can now run several times per second, all performed locally. No connection to Google cloud required. (See our earlier coverage for more technical details.) The default demo application of a Google AIY Vision kit is a “joy detector” that looks for faces and attempts to determine if a face is happy or sad. We’ve previously seen this functionality mounted on a robot dog.
[Alex] aimed to go beyond the default app (and default box) to create Archimedes, who was to reward happy people with a sticker. As a moving robotic owl, Archimedes had far more crowd appeal than the vision kit’s default cardboard box. All the kit components have been integrated into Archimedes’ head. One eye is the expected Pi camera, the other eye is actually the kit’s piezo buzzer. The vision kit’s LED-illuminated button now tops the dapper owl’s hat.
Archimedes was created to join in Google’s promotion efforts. Their presence at this Maker Faire consisted of two tents: one introductory “Learn to Solder” tent where people can create a blinky LED badge, and the other tent is focused on their line of AIY kits like this vision kit. Filled with demos of what the kits can do aside from really cool robot owls.
Hopefully these promotional efforts helped many AIY kits find new homes in the hands of creative makers. It’s pretty exciting that such a powerful and inexpensive neural net processor is now widely available, and we look forward to many more AI-powered hacks to come.
When the time comes to add an object recognizer to your hack, all you need do is choose from many of the available ones and retrain it for your particular objects of interest. To help with that, [Edje Electronics] has put together a step-by-step guide to using TensorFlow to retrain Google’s Inception object recognizer. He does it for Windows 10 since there’s already plenty of documentation out there for Linux OSes.
You’re not limited to just Inception though. Inception is one of a few which are very accurate but it can take a few seconds to process each image and so is more suited to a fast laptop or desktop machine. MobileNet is an example of one which is less accurate but recognizes faster and so is better for a Raspberry Pi or mobile phone.
You’ll need a few hundred images of your objects. These can either be scraped from an online source like Google’s images or you get take your own photos. If you use the latter approach, make sure to shoot from various angles, rotations, and with different lighting conditions. Fill your background with various other things and even have some things partially obscuring your objects. This may sound like a long, tedious task, but it can be done efficiently. [Edje Electronics] is working on recognizing playing cards so he first sprinkled them around his living room, added some clutter, and walked around, taking pictures using his phone. Once uploaded, some easy-to-use software helped him to label them all in around an hour. Note that he trained on 24 different objects, which are the number of different cards you get in a pinochle deck.
You’ll need to install a lot of software and do some configuration, but he walks you through that too. Ideally, you’d use a computer with a GPU but that’s optional, the difference being between three or twenty-four hours of training. Be sure to both watch his video below and follow the steps on his Github page. The Github page is kept most up-to-date but his video does a more thorough job of walking you through using the software, such as how to use the image labeling program.
Why is he training an object recognizer on playing cards? This is just one more step in making a blackjack playing robot. Previously he’d done an impressive job using OpenCV, even though the algorithm handled non-overlapping cards only. Google’s Inception, however, recognizes partially obscured cards. This is a very interesting project, one which we’ll be keeping an eye on. If you have any ideas for him, leave them in the comments below.
Readers of a certain vintage will remember the glee of building your own levels for DOOM. There was something magical about carefully crafting a level and then dialing up your friends for a death match session on the new map. Now computers scientists are getting in on that fun in a new way. Researchers from Politecnico di Milano are using artificial intelligence to create new levels for the classic DOOM shooter (PDF whitepaper).
While procedural level generation has been around for decades, recent advances in machine learning to generate game content (usually levels) are different because they don’t use a human-defined algorithm. Instead, they generate new content by using existing, human-generated levels as a model. In effect they learn from what great game designers have already done and apply those lesson to new level generation. The screenshot shown above is an example of an AI generated level and the gameplay can be seen in the video below.
The idea of an AI generating levels is simple in concept but difficult in execution. The researchers used Generative Adversarial Networks (GANs) to analyze existing DOOM maps and then generate new maps similar to the originals. GANs are a type of neural network which learns from training data and then generates similar data. They considered two types of GANs when generating new levels: one that just used the appearance of the training maps, and another that used both the appearance and metrics such as the number of rooms, perimeter length, etc. If you’d like a better understanding of GANs, [Steven Dufresne] covered it in his guide to the evolving world of neural networks.
While both networks used in this project produce good levels, the one that included other metrics resulted in higher quality levels. However, while the AI-generated levels appeared similar at a high level to human-generated levels, many of the little details that humans tend to include were omitted. This is partially due to a lack of good metrics to describe levels and AI-generated data.
Example DOOM maps generated by AI. Each row is one map, and each image is one aspect of the map (floor, height, things, and walls, from left to right)
We can only guess that these researcher’s next step is to use similar techniques to create an entire game (levels, characters, and music) via AI. After all, how hard can it be?? Joking aside, we would love to see you take this concept and run with it. We’re dying to play through some gnarly levels whipped up by the AI from Hackaday readers!
First Google gradually improved its WaveNet text-to-speech neural network to the point where it sounds almost perfectly human. Then they introduced Smart Reply which suggests possible replies to your emails. So it’s no surprise that they’ve announced an enhancement for Google Assistant called Duplex which can have phone conversations for you.
What is surprising is how well it works, as you can hear below. The first is Duplex calling to book an appointment at a hair salon, and the second is it making reservation’s with a restaurant.
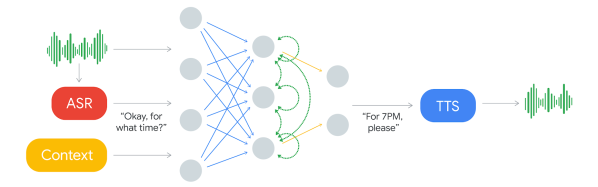
Note that this reverses the roles when talking to a computer on the phone. The computer is the customer who calls the business, and the human is on the business side. The goal of the computer is to book a hair appointment or reserve a table at a restaurant. The computer has to know how to carry out a conversation with the human without the human knowing that they’re talking to a computer. It’s for communicating with all those businesses which don’t have online booking systems but instead use human operators on the phone.
Not knowing that they’re talking to a computer, the human will therefore speak as it would with another human, with all the pauses, “hmm”s and “ah”s, speed, leaving words out, and even changing the context in mid-sentence. There’s also the problem of multiple meanings for a phrase. The “four” in “Ok for four” can mean 4 pm or four people.
The component which decides what to say is a recurrent neural network (RNN) trained on many anonymized phone calls. The input is: the audio, the output from Google’s automatic speech recognition (ASR) software, and context such as the conversation’s history and the parameters of the conversation (e.g. book places at a restaurant, for how many, when), and more.
Producing the speech is done using Google’s text-to-speech technologies, Wavenet and Tacotron. “Hmm”s and “ah”s are inserted for a more natural sound. Timing is also taken into account. “Hello?” gets an immediate response. But they introduce latency when responding to more complex questions since replying too soon would sound unnatural.
There are limitations though. If it decides it can’t complete a task then it hands the conversation over to a human operator. Also, Duplex can’t handle a general conversation. Instead, multiple instances are trained on different domains. So this isn’t the singularity which we’ve talked about before. But if you’re tired of talking to computers at businesses, maybe this will provide a little payback by having the computer talk to the business instead.
On a more serious note, would you want to know if the person you were speaking to was in fact a computer? Perhaps Google should preface each conversation with “Hi! This is Google Assistant calling.” And even knowing that, would you want to have a human conversation with a computer, knowing that it’s “um”s were artificial? This may save time for the person whom the call is on behalf of, but the person being called may wish the computer would be a little more computer-like and speak more efficiently. Let us know your thoughts in the comments below. Or just check out the following Google I/O ’18 keynote presentation video where all this was announced.





 You’ll need a few hundred images of your objects. These can either be scraped from an online source like Google’s images or you get take your own photos. If you use the latter approach, make sure to shoot from various angles, rotations, and with different lighting conditions. Fill your background with various other things and even have some things partially obscuring your objects. This may sound like a long, tedious task, but it can be done efficiently. [Edje Electronics] is working on recognizing playing cards so he first sprinkled them around his living room, added some clutter, and walked around, taking pictures using his phone. Once uploaded, some easy-to-use software helped him to label them all in around an hour. Note that he trained on 24 different objects, which are the number of different cards you get in a
You’ll need a few hundred images of your objects. These can either be scraped from an online source like Google’s images or you get take your own photos. If you use the latter approach, make sure to shoot from various angles, rotations, and with different lighting conditions. Fill your background with various other things and even have some things partially obscuring your objects. This may sound like a long, tedious task, but it can be done efficiently. [Edje Electronics] is working on recognizing playing cards so he first sprinkled them around his living room, added some clutter, and walked around, taking pictures using his phone. Once uploaded, some easy-to-use software helped him to label them all in around an hour. Note that he trained on 24 different objects, which are the number of different cards you get in a