
When do you need to use a real-time operating system (RTOS) for an embedded project? What does it bring to the table, and what are the costs? Fortunately there are strict technical definitions, which can also help one figure out whether an RTOS is the right choice for a project.
The “real-time” part of the name namely covers the basic premise of an RTOS: the guarantee that certain types of operations will complete within a predefined, deterministic time span. Within “real time” we find distinct categories: hard, firm, and soft real-time, with increasingly less severe penalties for missing the deadline. As an example of a hard real-time scenario, imagine a system where the embedded controller has to respond to incoming sensor data within a specific timespan. If the consequence of missing such a deadline will break downstream components of the system, figuratively or literally, the deadline is hard.
In comparison soft real-time would be the kind of operation where it would be great if the controller responded within this timespan, but if it takes a bit longer, it would be totally fine, too. Some operating systems are capable of hard real-time, whereas others are not. This is mostly a factor of their fundamental design, especially the scheduler.
In this article we’ll take a look at a variety of operating systems, to see where they fit into these definitions, and when you’d want to use them in a project.
A Matter of Scale
Different embedded OSes address different types of systems, and have different feature sets. The most minimalistic of popular RTOSes is probably FreeRTOS, which provides a scheduler and with it multi-threading primitives including threads, mutexes, semaphores, and thread-safe heap allocation methods. Depending on the project’s needs, you can pick from a number of dynamic allocation methods, as well as only allow static allocation.
On the other end of the scale we find RTOSes such as VxWorks, QNX and Linux with real-time scheduler patches applied. These are generally POSIX-certified or compatible operating systems, which offer the convenience of developing for a platform that’s highly compatible with regular desktop platforms, while offering some degree of real-time performance guarantee, courtesy of their scheduling model.
Again, an RTOS is only and RTOS if the scheduler comes with a guarantee for a certain level of determinism when switching tasks.
Real-Time: Defining ‘Immediately’
Even outside the realm of operating systems, real-time performance of processors can differ significantly. This becomes especially apparent when looking at microcontrollers and the number of cycles required for an interrupt to be processed. For the popular Cortex-M MCUs, for example, the interrupt latency is given as ranging from 12 cycles (M3, M4, M7) to 23+ (M1), best case. Divide by the processor speed, and you’ve got a quarter microsecond or so.
In comparison, when we look at Microchip’s 8051 range of MCUs, we can see in the ‘Atmel 8051 Microcontrollers Hardware Manual’ in section 2.16.3 (‘Response Time’) that depending on the interrupt-configuration, the interrupt latency can be anywhere from 3 to 8 cycles. On x86 platforms the story is more complicated again, due to the somewhat convoluted nature of x86 IRQs. Again, some fraction of a microsecond.
This latency places an absolute bound on the best real-time performance that an RTOS can accomplish, though due to the overhead from running a scheduler, an RTOS doesn’t come close to this bound. This is why, for absolute best-of-class real-time performance, a deterministic single polling loop approach with fast interrupt handler routines for incoming events is by far the most deterministic.
If the interrupt, or other context switch, costs cycles, running the underlying processor faster can also obviously reduce latency, but comes with other trade-offs, not the least of which is the higher power usage and increased cooling requirements.
Adding Some Cool Threads
As FreeRTOS demonstrates, the primary point of adding an OS is to add multi-tasking (and multi-threading) support. This means a scheduler module that can use some kind of scheduling mechanism to chop the processor time into ‘slices’ in which different tasks, or threads can be active. While the easiest multi-tasking scheduler is a cooperative-style one, where each thread voluntarily yields to let other threads do their thing, this has the distinct disadvantage of each thread having the power to ruin everything for other threads.
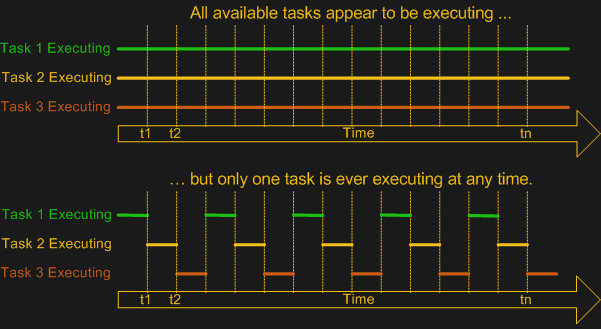 Most real-time OSes instead use a preemptive scheduler. This means that application threads have no control over when they get to run or for how long. Instead, an interrupt routine triggers the scheduler to choose the next thread for execution, taking care to differentiate between which tasks are preemptable and which are not. So-called kernel routines for example might be marked as non-preemptable, as interrupting them may cause system instability or corruption.
Most real-time OSes instead use a preemptive scheduler. This means that application threads have no control over when they get to run or for how long. Instead, an interrupt routine triggers the scheduler to choose the next thread for execution, taking care to differentiate between which tasks are preemptable and which are not. So-called kernel routines for example might be marked as non-preemptable, as interrupting them may cause system instability or corruption.
Although both Windows and Linux, in their usual configuration, use a preemptive scheduler, these schedulers are not considered suitable for real-time performance, as they are tuned to prioritize for foreground tasks. User-facing tasks, such as a graphical user interface, will keep operating smoothly even if background tasks may face a shortage of CPU cycles. This is what makes some real-time tasks on desktop OSes such a chore, requiring various workarounds.
A good demonstration of the difference with a real-time focused preemptive scheduler can be found in the x86 version of the QNX RTOS. While this runs fine on an x86 desktop system, the GUI will begin to hang and get sluggish when background tasks are performed, as the scheduler will not give the foreground tasks (the GUI) special treatment. The goal of the Linux kernel’s real-time patch also changes the default behavior of the scheduler to put the handling of interrupts first and foremost, while otherwise not distinguishing between individual tasks unless configured to do so by explicitly setting thread priorities.
RTOS or Not, That’s the Question
At this point it should be clear what is meant by “real-time” and you may have some idea of whether a project would benefit from an RTOS, a plain OS, or an interrupt-driven ‘superloop” approach. There’s no one-size-fits-all answer here, but in general one seeks to strike a balance between the real-time performance required and the available time and budget. Or in the case of a hobby project in far how one can be bothered to optimize it.
The first thing to consider is whether there are any hard deadlines in the project. Imagine you have a few sensors attached to a board that need to be polled exactly at the same intervals and the result written to an SD card. If any kind of jitter in between readings of more than a few dozen cycles would render the results useless, you have a hard real-time requirement of that many cycles.
 We know that the underlying hardware (MCU, SoC, etc.) has either a fixed or worst-case interrupt latency. This determines the best-case scenario. In the case of an interrupt-driven single loop approach, we can likely easily meet these requirements, as we can sum up the worst-case interrupt latency, the cycle cost of our interrupt routine (ISR) and the worst-case time it would take to process and write the data to the SD card. This would be highly deterministic.
We know that the underlying hardware (MCU, SoC, etc.) has either a fixed or worst-case interrupt latency. This determines the best-case scenario. In the case of an interrupt-driven single loop approach, we can likely easily meet these requirements, as we can sum up the worst-case interrupt latency, the cycle cost of our interrupt routine (ISR) and the worst-case time it would take to process and write the data to the SD card. This would be highly deterministic.
In the case of our sensors-and-SD-card example, the RTOS version would likely add overhead compared to the single loop version, on account of the overhead from its scheduler. But then imagine that writing to the SD card took a lot of time, and that you wanted to handle infrequent user input as well.
With an RTOS, because the samples need to be taken as close together as possible, you’d want to make this task non-preemptable, and give it a hard scheduling deadline. The tasks of writing to the SD card and any user input, with a lower priority. If the user has typed a lot, the RTOS might swap back to handling the data collection in the middle of processing strings, for instance, to make a timing deadline. You, the programmer, don’t have to worry about it.
In short: an RTOS offers deterministic scheduling, while an interrupt-driven single loop eliminates the need for scheduling altogether, aside from making sure that your superloop turns around frequently enough.
Creature Comforts
When one pulls away the curtain, it’s obvious that to the processor hardware, concepts like ‘threads’ and thread-synchronization mechanisms such as mutexes and semaphores are merely software concepts that are implemented using hardware features. Deep inside we all know that a single-core MCU isn’t really running all tasks simultaneously when a scheduler performs its multi-tasking duty.
Yet an RTOS – even a minimalistic one like FreeRTOS – allows us to use those software concepts on a platform when we simultaneously need to stay as close to the hardware as possible for performance reasons. Here we strike the balance between performance and convenience, with FreeRTOS leaving us to our own devices when it comes to interacting with the rest of the system. Other RTOSes, like NuttX, QNX and VxWorks offer a full-blown POSIX-compatible environment that supports at least a subset of standard Linux code.
While it’s easy to think of FreeRTOS for example as an RTOS that one would stuff on an MCU, it runs just as well on large SoCs. Similarly, ChibiOS/RT happily runs on anything from an 8-bit AVR MCU to a beefy x86 system. Key here is finding the right balance between the project requirements and what one could call creature comforts that make developing for the target system easier.
For RTOSes that also add a hardware abstraction layer (e.g. ChibiOS, QNX, RT Linux, etc.), the HAL part makes porting between different target systems easier, which can also be considered an argument in its favor. In the end, however, whether to go single loop, simple RTOS, complicated RTOS or ‘just an OS’ is a decision that’s ultimately dependent on the context of the project.















Not a bad write-up. There’s a few misc notes I have:
* While the article hinted at this, it didn’t quite come out and say that you need a preemptive scheduled for something to be considered real-time.
* One consideration when selecting an RTOS is the implications it has on your build system. For example, Apache MyNewt has its own custom build automation system (newt), but still uses the standard arm-none-eabi-gcc compiler. If I recall correctly, VxWorks and TI-RTOS only build from their respective customized versions of Eclipse, which can make build automation and CI cumbersome.
* Similar to above, some RTOS’s have requirements on the compilers they support. At the time I used VxWorks, they only supported their proprietary diab compiler. This meant constantly battling with the license server for getting your basic work done. (I think we can all agree that FlexLM is a blight on engineering in general.) TI-RTOS, if I recall correctly, uses a proprietary compiler from TI.
* It’s worth considering the language support the RTOS has. Most RTOS’s are written in pure C, which might mean being restricted to C in kernel, but allowing for C++ in application code.
* Last, some RTOS’s may have implications on how you write your driver code. TI-RTOS, for example, doesn’t care if your code interacts with the peripherals directly (as long as there isn’t an OS driver owning the peripheral), but with something like MyNewt, you’re probably going to be fighting with interrupt management issues when trying that approach.
On point one: you absolutely _don’t_ need a preemptive scheduler to get hard real time. Deterministic polling loops are the fastest / lowest-jitter way to go, in fact. If you don’t mind the jitter, you can do will with cooperative multitasking — which is actually my favorite.
But in both of these cases, the burden on being sure you make timing is on you. Cooperative systems are easy enough to get right as long as you can “yield” frequently enough in your tasks, and if things like UART and delays and so on are written with yielding in mind.
For me, pre-emptive systems open up a can of worms (mutexes, non-determinism, possible deadlocks) that you don’t need for 95% of the benefit of multi-tasking — hence my preference for cooperative, which is simpler and good enough.
And when the timing requirements are too tight for cooperative systems — you can’t yield often enough — then you’ve got to be _really_ careful with your RTOS as well. Might as well code stuff by hand at that point, IMO.
Of course, the popularity of RTOSes proves me wrong. :) So your mileage will most certainly vary.
I haven’t found any literature on static analyses to infer conservative worst-case bounds between resumption and yield points. This seems like it should be doable (with Frama-C maybe?) and could be used to ensure cooperative threads could satisfy hard real time bounds.
In my university class on Realtime architectures there was one lecture devoted to so called FPNS (Fixed Priority Nonpreemtive Scheduling) schedulability analysis.
Here is a reference to a paper where it is mentioned and how schedulability analysis is done.
https://pure.tue.nl/ws/files/2423979/200619.pdf
Thanks, you identified a key phrase to look for, “Fixed Priority Nonpreemtive Scheduling” which led to a bunch of papers. [1] has an overview of some work, but there has been more recent work too.
[1] https://link.springer.com/content/pdf/10.1007/978-3-540-72590-9_134.pdf
For soft real time systems, it is sufficient to measure the average latency over a large number of operations.
For hard real time systems the maximum latency must be determined; the average latency is irrelevant. Determining the maximum latency is *hard*, especially with unpredictable caches and interrupts. You can’t measure it, because the next operation might take a little longer!
You don’t mention a third alternative: put the RTOS in silicon. That is what XMOS do in their xCORE processors, and the development tools tell you the maximum time the operation will take; no measurement needed.
If that isn’t sufficient, the use an FPGA :)
You don’t have to put the whole RTOS in silicon, modern SOCs like the Raspi Pico have programmable hardware that can respond in real time without software overhead.
Minor nitpick: the Raspi Pico is a development board for the RP2040, which is an MCU (not an SOC).
While the programmable IO peripherals on the 2040 are cool, IO peripherals in general are not new. For decades, even fairly low-end MCUs have had some way of setting up a DMA to automatically handle data transfers from a UART, SPI, I2C, etc peripheral without the CPU’s involvement. There are also things like multicore MCUs, where you have a second core or low-power coprocessor taking care of I/O stuff.
Really, this is an extension of a bigger concept – the idea of offloading simple, repetitive, and time-sensitive tasks to dedicated cheap hardware. This is why a modern laptop might have several tens of microcontrollers inside it, and now we’re seeing microcontrollers with even simpler microcontrollers inside of them.
The need for an RTOS arises when you have a system that needs to do something more complex than a data transfer within a guaranteed amount of time. The field most familiar to me here is audio processing. You have a hard limit on when you need to push the next sample buffer, or else the user hears a “pop” (very bad during, say, a concert). At the same time, you need to run complex algorithms and maybe, say, handle input from a MIDI port and knobs. RTOS really helps get your priorities straight.
(This is not just a reply to you but to the article as well.)
Hard real-time systems have to produce an error when breaching hard real-time criteria.
With FreeRTOS hard real-time is possible. You have to set up task priorities watchdog feeding and SW checkpoints.
Let’s assume there is a time-slicing system.
The task with the highest frequency should have the highest priority and the slowest should have the lowest.
In contrast to that you should have a task that is feeding the watchdog. This task is somewhere in the mid range in terms of frequency (has to run every 20-40ms let’s say) but it should have the absolute lowest priority. This will ensure that the system is reset if real-time criteria is violated.
You can (and should) also do checks that your cyclic tasks’ gross cycle time (complete time to do an iteration of the infinite loop with interrupting tasks’ runtime) since you can’t be running the same iteration when you should be starting the next.
You can also have counting semaphores and a house keeping task to check if everything ran accordingly.
Real-time has to do with being deterministic (is deterministicity a word?). Some of the things I’ve seen so far (in safety critical systems)
– reduction of interrupt sources, and poll when possible. (since it’s harder to prove/measure the worst case when interrupts can happen any time)
– create code that has the same runtime in every branch (or number of iterations, again for worst case scenarios)
– limit CPU load to around 60-80% to mitigate for anything that was not measured calculated with
– usually the tasks are time triggered, and event triggered tasks are either short running or low prio. What you don’t want is have several event triggered high prio tasks that take a lot of CPU time.
In these case the maximum latency is not really predicted but the system will react to the violations of it. It should be considered as well, how does the timing requirements related to eg. the cache issues. If you have a controller running 100MHz, a few instructions to refresh the cache will be less than microsecond. But this moves the topic out from the software domain to the system design..
> … use an FPGA :)
My thoughts exactly. FPGA are so cheap and capable nowadays that you really should just use a FSM in an FPGA. Fixed function pipeline architectures means ‘interruption’ is impossible.
Latencies are measured by the nanosecond and jitter by the picosecond. Usually both just by whatever the moderate system synchronous clock is. 30 to 60 MHz or so typically works fine and generally requires no special techniques or additional effort to achieve.
Microcontrollers should be banished from all applications where hard-real time is necessary – they’re best where ‘low cost’ and/or ‘absolute minimum power’ are the most important design priorities.
Otherwise you just deploy an FPGA to do the important stuff, and an SoC with a full linux OS on it for the non-critical stuff like GUI’s and network communications. That way you get all the features that makes management and customers happy, and can also avoid needing to maintain an OS forever as well (if you do it right – don’t reinvent the distro!).
Truly Important communications should be handled directly by dedicated state machines on the FPGA / ASIC. But such things are generally not what you’d consider ‘communications’; more ‘digital plumbing’ between different sensors & actuator chips. FPGA’s are *really* good at this!
The real reason why you should avoid RTOS: is that ‘feature creep’ is absolutely a thing. And you will, at some point, simply have to handle it sensibly and gracefully.
On an FPGA, what happens as designs evolve is that you either start not meeting static timing, or you just run out of space. But until that point, adding just one more extra bit of functionality changes the timing of the existing functionality NOT AT ALL. Also, unlike a microcontroller, you really can trivially split designs over multiple chips.
On an RTOS system – that one ‘after thought’ task that management demands be tacked on? It can be the straw that breaks the camels back. In really nasty ways. Intermittent edge-case errors are very easy to have on programmable general-purpose processor. It could pass all testing in the lab, and die at random in the wild. Especially so if you expect that one poor guy to do everyone’s job at once!
Don’t forget what an OS IS: It’s a way to *share* the CPU. If you are engineering a critical system – it should have dedicated resources! Not be shared! OS and RTOS (even VM’s, funnily enough) were great solutions, invented for the Apollo mission computers. Because resources really *were* that tight that they really didn’t have a choice. Look it up.
So: banish any OS from the critical bits, and have the FPGA simply dedicate state machines which can by (your!) design never have their shoulders bumped.
I mean, think why ‘network cards’ and ‘sound cards’ and ‘video cards’ exist: So that fixed function hardware, can just get the job done, reliably. Original ‘personal computers’ like the Apple 1 and ][ had just the one microcontroller — for reasons of cost.
What it boils down to, is that RTOS were a solution for a by-gone era.
FPGA’s effectively make near-ASIC performance (or close enough to be ‘good enough’) cheap enough and low-risk enough for all.
And because SoC’s are themselves now so capable, if you really need internet capabilities – you can just have a whole embedded Unix-like stack in there. Or if cost is a concern, use something like the ESP chips – let them just be ‘communications subsystems’ and never fully trust them: They could always be ‘owned’ without warning, after all.
Intermediate SoC’s like the ARM chips on the bigger Teensys fill the gap in between. Cases where you might want to run tensorflow embedded.
If you still need an RTOS – then pick one that’s SMALL. Because if you need to make performance guarentees, you basically will need to take 100% responsibility for all code on that chip!
So you’d better have read through all the source and understand how it all fits together and works – none of this ‘just trust the OS’! KISS.
Or else go back to using a full open source OS stack and just not trust it for any critical tasks. If you’re going to trust : Trust but verify. And leave yourself a support path that makes that can of worms none of your business!
Last but not least: Consider repairability. If you’re using a bespoke system image, it’s going to be a black box for whoever inherits it. Probably landfill or a grinder. If, on the other hand, it’s a recognisable known platform (like a raspi), AND/OR with a recognisable FPGA on it: It’s at least got a chance to be reused by some random kid down the track.
Great point in case: https://github.com/kholia/Colorlight-5A-75B
These are boards meant for big video LED displays, but because they just-so-happened to include an FPGA with OSS toolchain support (and have two gigabit MAC’s!): They make extremely available and capable development boards.
You can hook them up in a loop of a large number of these, and use the MAC’s like EtherCAT (but at gigabit speeds! Essentially a chained shift-register, sort of like token-ring but not having to wait for the packet to finish arriving before it
is forwarded on around the loop) so you can have hard, realtime, and ultra-low latency communications throughout your distributed control system.
Or you can implement just enough to be able to do UDP, and use them to stream data from sensors in the field in to a NAS or processing datacenter – maybe an array of raspis to reprocess video on the fly.
Even without GHz level clocks, FPGA’s are much quicker than you’d expect, being used to systems with just one CPU. Or conversely: GHz clocked CPU’s (but backed by uncertain latency DRAM) are much slower than you’d think – it’s just that you’re used to it, and high numbers look good for marketing.
Right now Symbiflow is where GCC was when Linux had just become a thing. Get in on it!
One of the biggest impact of RTOS use is the memory, not the task or latency.
It is easier to optimize memory in bare metal or simple function schedulers, but RTOS requires allocated stacks for each tasks, its own internal structures and user primitives. This can add-up really quick.
For me the only “real” RTOS left is Amazon FreeRTOS: it does not try to push a framework down your throat. It’s easy to port and understand. Its licence is the easiest to deal with.
The only downside is that it is quite difficult to debug, has some quirks between ports (scheduler behavior is different between arm and risc-v port for example).
ChibiOS is quite nice but is crippled by antediluvian source control (svn? come on it’s 2021!), triple licencing (apache, GPL/proprietary) and it comes with it’s own build system (makefiles).
Most other RTOS I know are more or less full software environment with RTOS in them (zephyr, nuttx and so on) so not really attractive for the hacker.
Yep. Allocated stack for each task. I remember in VRTX we had to set aside a block of memory for the array of tasks that were going to be running. There was a defined size formula that you would calculate and then give Vrtx the offset to it. I really liked it for its ‘simplicity’ as really we used three things: locks, pend/post, delay() and of course each task had a priority 0 – 255. If a priority task 0 (highest priority) wanted to ‘hog’ the machine then that’s what happens. It’s an RTOS. I need to take a look at freeRTOS again….
It’s important to note that some RTOS’ offer POSIX compatibility, not compliance. The difference is they are missing large numbers of POSIX functions entirely and their behavior may be the same as POSIX.
The term POSIX compatibility is so common because POSIX is a registered trademark of The Open Group and it is a violation of that trademark to use it without some caveats. POSIX compliance means that you have passed the POSIX compliance test suite and you are all squared up with The Open Group.
I work with NuttX and we say POSIX compatible for legal reasons, not because there are “missing large numbers of POSIX functions” or because there is an issue with the behavior of the interfaces.
One of my favorite moments of this discussion: Gregory Nutt says he “works with NuttX” :D You’re a humble gentleman.
I am no longer the BDFL of NuttX. I am just a regular contributor these days. At the end of 2019, NuttX became Apache NuttX and is now a fully community owned and managed project. https://nuttx.apache.org/
Opps… s/The Open Group/IEEE/g
I am confused as usual. IEEE holds the trademark on POSIX. POSIX compliance implies that the OS has been ran against the IEEE POSIX certification tests. The steps to claim POSIX certification are here: http://get.posixcertified.ieee.org/
The Open Group holds the trademark “Unix” which also requires some care (and leads to my confusion). Linus Torvalds holds the trademark Linux.
NuttX is tested using the Linux Test Project (LTP) but true POSIX certification is out of the reach of most open source projects.
Back in about ’96-ish… “posix compatible” meant “We changed over to elf binaries from a.out and re-ordered the file system a bit.”
The Last real RTOS was DOS on a simpler cpu.
As processors became more complex, the predictability and variability of their latency got worse. Most Guaranteed latency schedulers are often a naive last resort (i.e. those that don’t understand what happens during interrupt service routines). One of the more obscure features of RTLinux is that it can use externally clocked schedulers with io signals, and thus synchronize several concurrent processes (on multiple cpus etc.) to a single accurate event time.
Even FPGAs won’t have zero logic propagation delay… sure it may work in synthesis, but it can be physically impossible to build some designs. Clock domain crossing and misbehaved latch logic are real design constraints, that only have a finite set of workarounds.
FreeRTOS actually is fairly decent, but the fact Amazon owns it now means it’s not something everyone is comfortable with integrating. ;-)
https://www.youtube.com/watch?v=G2y8Sx4B2Sk
Oh here comes the half-true FUD.
Seriously, DOS was by itself never an RTOS, and thinking that machines that run DOS back in the day had a better determinism on timing on the same timescales as a modern RTOS on a modern microcontroller is pure faux nostaligia, not based in facts. I’ll gladly take the DOS-running microprocessor with the couple-of-nanosecond accurate timer that competes with a Cortex-R + modern RTOS as a counterargument. If the argument is “my CNC runs DOS, and I have very fond feelings for that”, I’ve got bad news for you.
MCUs/processors that needed to be deterministic in latency got better at that. Processors that needed to crunch a lot of numbers got better at that. Just because your Zen2 PC’s latency is nominally less reliable than that of your DOS machine doesn’t mean, at all, that all machines out there got less accurate. The opposite is the case: MCUs for RT applications, especially things like motor control and safety features, got a lot better. And the classic argument in the PC world is that even memory access on a modern PC can take much longer than it took on a PS/2. Yeah, that’s true if you address arbitrary addresses in its multi-GB RAM. Now, the PS/2 had about as much RAM in total as larger L1 caches on CPUs…
And you’re really missing the whole point of deterministic latency, too. It doesn’t have to be infinitely low (as you note, that’s impossible), it has to be bounded. And that’s the case. “Real Time” doesn’t mean “instant”, it means “guaranteed within some specified time”.
Study on “Computer latency: 1977-2017” ( https://danluu.com/input-lag/ )
And no, when you get two machines trying to do concurrent tasks in sync, you will run into issues your guaranteed latency scheduler jitter stats cannot know while running on the same PC cpu/bus.
FUD is generally associated with baseless rhetoric, and none of these statements are false. Old DOS machines with ISA bus cards are still in use today inside legacy equipment. Some people attempt to modernize such machines. but usually this involves tossing everything to start over.
In general, most modern control platforms will physically separate the multitasking-environment from time-critical embedded control firmware as necessitated. I think we can both agree that there are reasons beyond more efficient computation of problems on a more complex cpu,
If you still think modern sub-30nm process cpus are more reliable than the original Motorola 68HC hardened series with parity checked large cells, than chances are you honestly don’t know what you missed.
Further details may be found in the user page link ;-)
Terminal input-to-screen lag in general purpose OS’s isn’t really indicative of CPU task latency or a CPU’s ability to maintain low-jitter and low latency schedules though, is it?
“application decides what to do with the event; apps are poorly written, so usually this takes many ms.”
“the actual amount of work happening here is typically quite small. A few ms of CPU time. Key overhead comes from:
periodic scanrates (input device, render server, display) imperfectly aligned
many handoffs across process boundaries, each an opportunity for something else to get scheduled instead of the consequences of the input event
lots of locking, especially across process boundaries, necessitating trips into kernel-land”
So, what the article is saying is that the newer OS’s have longer process pipelines between keyboard and monitor, and that application software sucks. Nowhere does it say that the new processors are incapable of low latency performance in any given task, nor for that matter, that old ones are capable.
DOS is a single task OS, which is great if you only need a single task to ever run and can code that task completely deterministically. Otherwise you’d have to implement your own scheduler and process model. Beckoff did that in 1988 with their S1000 software, scheduling an NC task, a single software PLC and a UI task in a single DOS app. Guess which task had the lowest priority? (*) On-time will sell you RTKernel that does the same thing. I’m sure there are others.
(*) Yes, the UI task had the lowest priority, thus the highest worst-case latency. That’s why the study produced as evidence made me LOL. When the sensors tell you that the shit has hit the fan, you make sure that you turn the fans off before polling for user input, or updating their display. Input-to-screen lag is at best meaningless, but usually, a sign that the CPU has better things to do, and that is especially true in real-time.
Some good points, but the dynamic nature of the throughput is more probabilistic on modern PC architectures for reasons beyond contention and caches. CPU thermal-throttling clock-speeds and ram refresh times are both affected by temperature, so “turning on a fan” would also change the identical codes execution time.
This means one can never really know how long some io operation will take with 100% certainty unless buffered by something that is of much simpler design internally (often a hardware fifo in VHDL that isolates each clock domain). My point was profiling code running inside a PC machine is impractical as is can’t really be unaware of the timing skew it would create in the real world each time it ran, and RTOS usually make a statistical estimate from the RTC which has a timing granularity that hasn’t changed much in 40 years.
It is like those that think Arduino’s are predictable with a fixed clock speed, but haven’t discovered that by default a configured timer is interrupting their code constantly.
Sorry, benchmarks of keypress-display or browser scroll delays, which are not at all considered realtime tasks, has exactly nothing to do with whether the hardware or the OS are better at keeping realtime constraints.
This has something to do with application software. Nothing here benefits from realtime-capability, because nothing uses any of that.
Don’t apologize for not understanding that my point was calling guaranteed-latency schedulers a Real-Time anything was deceptive and naive. Your PC keyboard almost certainly has a buffer in a chip that also scans input, and runs inside its own clock domain.
Someone that has never seen a platypus would surely think they were fictional. ;-)
There are good and valid points you make.
In many micro-controllers you’ll find co-processors that you can utilize to extreme real-time needs.
eTPU on the NXP (Freescale) MPC controllers, or the PRUs on the TI sitara line. Even if you think about it, the M4 core in the STM32H7 or STM32MP1 can be used similarly. Usually a microcontroller will not handle many such functions. (In a car you’ll find several real-time controllers doing different real-time tasks, not a single one doing many.)
You are right about propagation delays in all sorts of stuff BUT, you have to consider whether that delay is considerable in the the system. A temperature control can be real-time with seconds or hours reaction time as well. Does it matter that the controller has microseconds delay? I’m sure, that for highly specialized tasks if the timing criteria is so tight they could do an ASIC if really needed.
It’s also true that older controllers were not as prone to soft errors, although you can’t clock them as high or can’t keep them in the same thermal envelope. This is a tradeoff that you have to consider. Higher clock can reduce delays in system reaction (although still requires considerations like putting code in RAM, as flash access might need more wait states etc..)
With consumer electronics and related SW there is a lot of SW abstraction and layers upon layers for compatibility or such, and indeed the response times are increasing. Btw this abstraction hell is also happening in automotive as everyone wants to reuse every piece of code.. but this is more related to management requirements and SW engineering practices.
FreeRTOS is still under the MIT license, so the fact that it’s sponsored by AWS seems irrelevant.
There is more than one RT-patch for Linux.
In addition to the preempt-rt patch (which is now nearly mainline) there is also RTAI and Xenomai.
http://www.rtai.org
https://gitlab.denx.de/Xenomai/xenomai/-/wikis/home
Typically RTAI will give lower latency than preempt-rt on x86 hardware, though that depends unpredictably on the hardware.
I have an old-ish education PC (Research Machines RM-One all-in-one) that attains latency < 2µS with both preempt-rt and RTAI.
I did some “research” real time Linux around 2004. My university was using Matlab/Simulink with xpc target (or something) but licence was quite expensive. I was asked to check if this could be partially replaced with some real time linux solution. I found RTAI and Scilab/Scicos are cooperating quite good. Soon I wrote a LPT step motor controller block for Scicos using “c block” which was very painful few linaes of C (I did not know C and Scicos editor did not save your changes if you made any mistake plus it was using Emacs shortcuts so I didn’t know how to copy paste that). I was new to Linux, C, real time, Scilab and in fact almost everything related. Most importantly it was noticed that a lot of money could be saved but no one wanted to drop Matlab/Simulink. Can’t blame them. Some things were just to painful even for Linux enthusiast. I did some read-write test through oscilloscope and LPT. But today I know this test should be done better.
Anyway I see that there is some support for Arduino for this solution now so they evolve a bit.
Been developing the Miosix RTOS for a while (10+ years) and reading hackaday for around the same time, so I guess “advertising” it seems legit. Free software, the best feature is its C++ integration. The C++11 thread API is nice and as far as I know Miosix is one of the few solutions that make it available in a 32 bit microcontroller environment, but pthreads are supported too.
Goes as far as to patch the GCC compiler to “teach” it the Miosix thread model so that things like C++ exceptions and every aspect of the C and C++ standard libraries is safe to be concurrently used by multiple threads.
A few years ago there was an article regarding SST, the Super Simple Tasker. An RTOS that uses a microprocessor’s built-in stack and interrupt support to effectively manage several tasks with the caveat that they run to completion. This saves memory and reduces complexity as well as task switching time. I went looking for the article and the code is up on GitHub, along with the article. https://github.com/QuantumLeaps/Super-Simple-Tasker.
LinuxCNC assumes that the real time code will run to completion too. I don’t know if this is necessary for preempt-rt but it is for RTAI.
If the real-time interrupt is the No1 priority on the machine then I think that you pretty much _have_ to let the real-time code run to completion.
In practical terms this is done with state machines, built (in C, as RTAI runs a Linux kernel code) with “switch” statements.
switch(state){
case 0: // dormant
if (thing) state = 1, timer = 1000;
break;
case 1:
if ((timer -= fperiod) < 0) state = 3;
break;
and so-on. No busy-waits, runs a very few lines of code, and exits.
+1 for SST and run to completion schedulers in general. I often find it to be a nice middle ground between plain old loops and interrupts and a full blown RTOS. Simple to get your head around but scales up nicely, especially for event driven software
And protothreads, if you’re going down that path.
http://dunkels.com/adam/pt/
Yep, I am using prioritized preemptive run to completion OS as well. I wanted to learn how it works so I wrote one myself at the end.
Awesome post. I have one question: Whats a interrupt driven single loop? Can you post an example?
Thanks!
Basically you have a single loop which contains all the tasks the program is to perform and that is called by a timer interrupt at a set rate. This is about the simplest form of RTOS, but is only really suitable for simple tasks
It can be made quite powerful when the CPU has interrupt priorities so that you can do a bunch of real time stuff in the interrupt handlers.
This is actually pretty common in the industry. You have a single loop and all the logic blocks are executed sequentially from highest to lowest priority. There is a watchdog that makes sure the loop cycle finishes in the given time. This provides guaranteed response times when all you need is reaction in 1 ms or so.
It’s actually pretty much what LinuxCNC does (with any of the RTOS systems that it supports)
There is a list of functions that are called in strict sequence every 1mS.
The functions themselves are defined by the input (HAL) file, and added to the thread list in the required sequence.
Each runs to completion, and the next is then started.
In some cases there is a fast thread (typically running every 25uS) which works in just the same way, but usually does only very basic things with integer arithmetic, such as counting encoder pulses or making stepper steps.
The fast thread can interrupt the slow thread. But many machines offload the fast thread work to an FPGA and use only a single “servo” thread.
This is exactly how millions of PLCs work.
This programming techniqe is easy to understand, doesn’t require complex synchronisation mechanisms and the determinism is pretty good. Debugging is easy and also the worst case processing time can be easily measured and logged. It’s a quality indicator for the robustness and architecture of the whole system.
(BTW: Finding the worst case scenario for a system is one of the most challenging task to find out. And I expect only a few programmers really know the worst case scenario for their systems. The most common approach is testing some expected worst case scenarios and getting some timing information out of it. This is simple for this programming technique, but really difficult for a event based system when different tasks are involved. How can you find out how far the crash is?)
The disadvantage is that this programming technique is a polling approach, which therefore introduces some overhead and additional cycles to check if something has to be done – even if nothing has to be done. For an event driven system these checks are obsolete. Also the CPU is not allowed to be 100% utilized – not even in one single cycle. And all software components has to be aware of the cooperative multitasking approach and need to make sure not to run too long. I think this is the most problematic thing when you want to use some middleware like protocol stacks. They often need a tasking environment.
Nevertheless, due to the continous recalculation of the system state of a polling system in every cycle the application is more robust – even when some minor bugs exist. For example one single missed interrupt for an event based system leads mostly to a data loss and disfunction. For a cyclic based system which recalculates its state on every cycle, there is a real chance that one missed system event is discovered and processed in the next cycle. So the effects of the bug are only visible for a few microseconds. In the next cycle the system is in a sane state again.
So I think when you have enough CPU power and have some mid range timing or response time requirements (~1ms) this approach is really easy and robust.
It’s a common misconception that realtime means fast. Realtime means “in a defined time”. The best example for non-realtime behavior is cooperative multitasking when the task switch happens sometime from instant to never.
And a non realtime OS on a fast CPU would still be faster in most cases than a realtime OS on a slow CPU.
Yes, task jitter is sometimes more critical than mean performance. We hit this problem with AMD embedded processors. In theory they had good price performance, but we found they had a very aggressive power management, which meant when they got hotter they would slow the clock down to reduce power consumption. On a PC, you would never notice, but when you have very time dependent loops, it was terrible.
Why does RTAI (LinuxCNC) make the GUI feel *more* responsive on slower hardware (Atom D510, i3-3240) than on a modern (-generic) platform?
Nowadays there is also Microsoft’s RTOS (https://azure.microsoft.com/en-us/services/rtos). And I also wonder why mbed-os (https://os.mbed.com/mbed-os/) was not mentioned. They offer a nice ecosystem and they have a large number of supported boards. They have an Arduino like abstraction layer so it really easy to dive into.
Microsoft RTOS is ThreadX, but the licence is not opensource.
Mbed is close to what zephyr is, more of an environment and very hard to find true project using them, it’s much more a kind of “we have basilion examples and board support but much less true users”
Was about to point out the same thing. If someone actually cares about good code quality, they probably won’t stand FreeRTOS. There’s a reason Express Logic’s ThreadX had deployments in order of billions, while not being open source and before Microsoft even bought them…
99% of the time you just need cooperative OS.
RTOS will cause a lot of headaches for the last 1%.
Exactly this. Cooperative OS is so much simpler. Add some interrupt priorities for real time stuff, if necessary.
Unfortunately, that 1% is usually the important bit that keeps chemical processes from doing bad things, machines from crashing, power substations from imploding, and other things that are generally critical to life.
A task on a cooperative OS is at the mercy of every other task. With the complexity of modern computer systems, especially in the age in connectivity and the need for vulnerability remediation, that’s problematic. It’s hard enough to test software for functionality, let alone find that one weird edge-case that makes it spin-lock.
“programmable hardware that can respond in real time without software overhead”. That is trivially true for all processors!
The point is about all the computations that cannot be done in generic hardware, and can only be done in software.
One example off the top of my head: capture samples at (say) 10MS/s, perform an FFT, stream it up a USB link, while driving a display and responding to user input. System fails if one input sample is missed :)
The data capture, display part can be done with DMA in a ping/pong buffer. FFT in software and the USB, inputs done in IRQ.
I think it is not that simple. Managing a screen is not limited to sending the frame to the hardware using DMA… and the management of the USB is often done using a “middleware” which we do not know if it is blocking or not. For example, the USB stack proposed by ST uses a DMA to transfer data, but has a waiting loop to wait for the DMA to be finished.
You don’t fix crappy middleware problems by running them on an RTOS, though.
>Managing a screen is not limited to sending the frame to the hardware using DMA
I have been there and done that – writing code to shift pixel out of DMA SPI.
The hard real time of “driving a display” is done in DMA as any cycle level jitter can cause the screen to distort. The rest can be IRQ or hardware depending if you have a real CRTC or are handing it in firmware.
USB is a complex protocol, but at the lowest level there was very little hard real time limits – I think there was one for figuring out if CRC is invalid and ask for resend. A few microcontrollers I looked at simply store the incoming packet in shared buffer memory, but flag the packet type. The firmware has to go through an IRQ *before* it can figure out what to do with it. e.g. Setup, standard USB commands, Custom, Polling for Interrupt packet etc. The firmware is responsible for packetizing/reassembling. IRQ goes before any DMA or processor buffer to memory transfer
Thank you for this pleasant article to read.
If you have “MicroC/OS-II” by Jean Labrosse, it came with a floppy on the inside back cover and all the source code. Today I think uC/OS-II and -III are open source and are maintained as an ongoing product by Micrium. It is a great book and he takes you along on the complete design of the OS and the code and algorithms that go with it. IIRC II and III are medical and flight qualified.
The kernel is written in ANSI C and some bits of assembly per the platform.
Don’t forget Riot-OS https://www.riot-os.org/
My opinion is that preemptive RTOSes are just too much trouble for what they’re worth. Essentially you are bringing in all the complexities of a fully threaded environment – you can’t just increment a global counter, examine a data structure that might be modified by another thread. You need to bring in synchronisation primitives like mutexes – which bring the possibility of deadlocks or livelocks, or mailboxes – which can create backpressure/spill related issues.
Also it needs mentioning, that due to how RTOSes muck about with the stack, more often than not, your debugger has trouble with the call stack of the currently executing thread – forget displaying the stacks of other threads like you could in
e.g. Windows. Also, the fact that each thread has its own stack, cuts deeply into the precious memory budget, 4 threads x 4K stacks, and half your usable memory is gone. Dynamic memory allocation tends to be a big no-no in RTOSes, so you have to preallocate all your threads, meaning you don’t really gain a lot of flexibility compared to a simple loop, but add tons. of complexity.
I think there’s a great solution for the problems RTOSes meant to address – like doing realtime while running a http stack in the background.
My company once did a multi channel real-time data collection thingy, which was accessible via a browser over WiFi, while logging its data to an SD card.
What we ended up doing is we put all the real-time parts on a microcontroller, which managed the sensors, processed the incoming data, and DMA’d the data over the SD card. Connected to it via SPI/serial was an embedded computer, essentially a full-fat ARM based non-realtime Linux distro.
All the complex, sophisticated internet-y parts were done on Linux – giving the devs the benefit of working in a familiar environment, and the microcontroller part was controlled by writing to the serial port tty file. When some high-bandwidth data transfer was needed, there was an SPI interface which was also accessible via file I/O.
Since there was 2 separate computers, the Linux part could in no way jeopardise the real-time behavior. An added benefit was, that the Linux part could go to sleep when not needed, essentially bringing down our power consumption close to what a pure microcontroller needed.
I have been developing software since 1982. For embedded, you want a pre-emptive run-to-completion scheduler (ideally a small footprint) like SST. You schedule your tasks to have the shortest tasks have the highest priority. This has been mathematically proven to be the optimal. If this fails some timing requirements, it will also fail when using cooperative scheduling.
Having inter-process constructs like messaging between tasks/threads in a microcontroller as offered by all/most “RTOS’s” is the stupidest thing you can do. Messaging is an inter-process (i.e. not sharing memory) mechanism, with no place in an embedded system, where all threads have access to the same memory.
With a pre-emptive scheduler you develop all your components as event-driven state machines (which is exactly what real-time systems do – they react to events). If you struggle with this, you should not be developing software, you should just be writing scripts.
It is close to impossible, if not completely impossible to ensure deterministic execution in cooperative systems and even if you could achieve all your timing requirements, you are completely dependent on other “threads” to ensure you meet them.