
Neural networks are all the rage right now with increasing numbers of hackers, students, researchers, and businesses getting involved. The last resurgence was in the 80s and 90s, when there was little or no World Wide Web and few neural network tools. The current resurgence started around 2006. From a hacker’s perspective, what tools and other resources were available back then, what’s available now, and what should we expect for the future? For myself, a GPU on the Raspberry Pi would be nice.
The 80s and 90s

For the young’uns reading this who wonder how us old geezers managed to do anything before the World Wide Web, hardcopy magazines played a big part in making us aware of new things. And so it was Scientific American magazine’s September 1992 special issue on Mind and Brain that introduced me to neural networks, both the biological and artificial kinds.
Back then you had the option of writing your own neural networks from scratch or ordering source code from someone else, which you’d receive on a floppy diskette in the mail. I even ordered a floppy from The Amateur Scientist column of that Scientific American issue. You could also buy a neural network library that would do all the low-level, complex math for you. There was also a free simulator called Xerion from the University of Toronto.
Keeping an eye on the bookstore Science sections did turn up the occasional book on the subject. The classic was the two-volume Explorations in Parallel Distributed Processing, by Rumelhart, McClelland et al. A favorite of mine was Neural Computation and Self-Organizing Maps: An Introduction, useful if you were interested in neural networks controlling a robot arm.
There were also short courses and conferences you could attend. The conference I attended in 1994 was a free two-day one put on by Geoffrey Hinton, then of the University of Toronto, both then and now a leader in the field. The best reputed annual conference at the time was the Neural Information Processing System conference, still going strong today.
And lastly, I recall combing the libraries for published papers. My stack of conference papers and course handouts, photocopied articles, and handwritten notes from that period is around 3″ thick.
Then things went relatively quiet. While neural networks had found use in a few applications, they hadn’t lived up to their hype and from the perspective of the world, outside of a limited research community, they ceased to matter. Things remained quiet as gradual improvements were made, along with a few breakthroughs, and then finally around 2006 they exploded on the world again.
The Present Arrives
We’re focusing on tools here but briefly, those breakthroughs were mainly:
- new techniques for training networks that go more than three or four layers deep, now called deep neural networks
- the use of GPUs (Graphics Processing Units) to speed up training
- the availability of training data containing large numbers of samples
Neural Network Frameworks
There are now numerous neural network libraries, usually called frameworks, available for download for free with various licenses, many of them open source frameworks. Most of the more popular ones allow you to run your neural networks on GPUs, and are flexible enough to support most types of networks.
Here are most of the more popular ones. They all have GPU support except for FNN.
Languages: Python, C++ is in the works
TensorFlow is Google’s latest neural network framework. It’s designed for distributing networks across multiple machines and GPUs. It can be considered a low-level one, offering great flexibility but also a larger learning curve than high-level ones like Keras and TFLearn, both talked about below. However, they are working on producing a version of Keras integrated in TensorFlow.
We’ve seen this one in a hack on Hackaday already in this hammer and beer bottle recognizing robot and even have an introduction to using TensorFlow.
Languages: Python
This is an open source library for doing efficient numerical computations involving multi-dimensional arrays. It’s from the University of Montreal, and runs on Windows, Linux and OS-X. Theano has been around for a long time, 0.1 having been released in 2009.
Languages: Command line, Python, and MATLAB
Caffe is developed by Berkeley AI Research and community contributors. Models can be defined in a plain text file and then processed using a command line tool. There are also Python and MATLAB interfaces. For example, you can define your model in a plain text file, give details on how to train it in a second plain text file called a solver, and then pass these to the caffe command line tool which will then train a neural network. You can then load this trained net using a Python program and use it to do something, image classification for example.
Languages: Python, C++, C#
This is the Microsoft Cognitive Toolkit (CNTK) and runs on Windows and Linux. They’re currently working on a version to be used with Keras.
Languages: Python
Written in Python, Keras uses either TensorFlow or Theano underneath, making it easier to use those frameworks. There are also plans to support CNTK as well. Work is underway to integrate Keras into TensorFlow resulting in a separate TensorFlow-only version of Keras.
Languages: Python
Like Keras, this is a high-level library built on top of TensorFlow.
Languages: Supports over 15 languages, no GPU support
This is a high-level open source library written in C. It’s limited to fully connected and sparsely connected neural networks. However, it’s been popular over the years, and has even been included in Linux distributions. It’s recently shown up here on Hackaday in a robot that learned to walk using reinforcement learning, a machine learning technique that often makes use of neural networks.
Languages: Lua
Open source library written in C. Interestingly, they say on the front page of their website that Torch is embeddable, with ports to iOS, Andoid and FPGA backends.
Languages: Python
PyTorch is relatively new, their website says it’s in early-release beta, but there seems to be a lot interest in it. It runs on Linux and OS-X and uses Torch underneath.
There are no doubt others that I’ve missed. If you have a particular favorite that’s not here then please let us know in the comments.
Which one should you use? Unless the programming language or OS is an issue then another factor to keep in mind is your skill level. If you’re uncomfortable with math or don’t want to dig deeply into the neural network’s nuances then chose a high-level one. In that case, stay away from TensorFlow, where you have to learn more about the API than Kera, TFLearn or the other high-level ones. Frameworks that emphasize their math functionality usually require you to do more work to create the network. Another factor is whether or not you’ll be doing basic research. A high-level framework may not allow you to access the innards enough to start making crazy networks, perhaps with connections spanning multiple layers or within layers, and with data flowing in all directions.
Online Services
Are you you’re looking to add something a neural network would offer to your hack but don’t want to take the time to learn the intricacies of neural networks? For that there are services available by connecting your hack to the internet.
We’ve seen countless examples making use of Amazon’s Alexa for voice recognition. Google also has its Cloud Machine Learning Services which includes vision and speech. Its vision service have shown up here using Raspberry Pi’s for candy sorting and reading human emotions. The Wekinator is aimed at artists and musicians that we’ve seen used to train a neural network to respond to various gestures for turning things on an off around the house, as well as for making a virtual world’s tiniest violin. Not to be left out, Microsoft also has its Cognitive Services APIs, including: vision, speech, language and others.
GPUs and TPUs
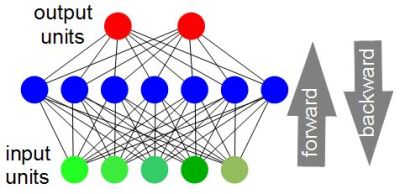
Training a neural network requires iterating through the neural network, forward and then backward, each time improving the network’s accuracy. Up to a point, the more iterations you can do, the better the final accuracy will be when you stop. The number of iterations could be in the hundreds or even thousands. With 1980s and 1990s computers, achieving enough iterations could take an unacceptable amount of time. According to the article, Deep Learning in Neural Networks: An Overview, in 2004 an increase of 20 times the speed was achieved with a GPU for a fully connected neural network. In 2006 a 4 times increase was achieved for a convolutional neural network. By 2010, increases were as much as 50 times faster when comparing training on a CPU versus a GPU. As a result, accuracies were much higher.

How do GPUs help? A big part of training a neural network involves doing matrix multiplication, something which is done much faster on a GPU than on a CPU. Nvidia, a leader in making graphics cards and GPUs, created an API called CUDA which is used by neural network software to make use of the GPU. We point this out because you’ll see the term CUDA a lot. With the spread of deep learning, Nvidia has added more APIs, including CuDNN (CUDA for Deep Neural Networks), a library of finely tuned neural network primitives, and another term you’ll see.
Nvidia also has its own single board computer, the Jetson TX2, designed to be the brains for self-driving cars, selfie-snapping drones, and so on. However, as our [Brian Benchoff] has pointed out, the price point is a little high for the average hacker.
Google has also been working on its own hardware acceleration in the form of its Tensor Processing Unit (TPU). You might have noticed the similarity to the name of Google’s framework above, TensorFlow. TensorFlow makes heavy use of tensors (think of single and multi-dimensional arrays in software). According to Google’s paper on the TPU it’s designed for the inference phase of neural networks. Inference refers not to training neural networks but to using the neural network after it’s been trained. We haven’t seen it used by any frameworks yet, but it’s something to keep in mind.
Using Other People’s Hardware
Do you have a neural network that’ll take a long time to train but don’t have a supported GPU, or don’t want to tie up your resources? In that case there’s hardware you can use on other machines accessible over the internet. One such is FloydHub which, for an individual, costs only penny’s per hour with no monthly payment. Another is Amazon EC2.
Datasets
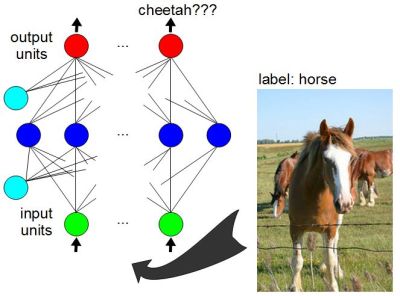
We said that one of the breakthroughs in neural networks was the availability of training data containing large numbers of samples, in the tens of thousands. Training a neural network using a supervised training algorithm involves giving the data to the network at its inputs but also telling it what the expected output should be. In that case the data also has to be labeled. If you give an image of a horse to the network’s inputs, and its outputs say it looks like a cheetah, then it needs to know that the error is large and more training is needed. The expected output is called a label, and the data is ‘labeled data’.
Many such datasets are available online for training purposes. MNIST is one such for handwritten character recognition. ImageNet and CIFAR are two different datasets of labeled images. Many more are listed on this Wikipedia page. Many of the frameworks listed above have tutorials that include the necessary datasets.
That’s not to say you absolutely need a large dataset to get a respectable accuracy. The walking robot we previously mentioned that used the FNN framework, used the servo motor positions as its training data.
Other Resources
Unlike in the 80s and 90s, while you can still buy hardcopy books about neural networks, there are numerous ones online. Two online books I’ve enjoyed are Deep Learning by the MIT Press and Neural Networks and Deep Learning. The above listed frameworks all have tutorials to help get started. And then there are countless other websites and YouTube videos on any topic you search for. I find YouTube videos of recorded lectures and conference talks very useful.
The Future

Doubtless the future will see more frameworks coming along.
We’ve long seen specialized neural chips and boards on the market but none have ever found a big market, even back in the 90s. However, those aren’t designed specially for serving the real growth area, the neural network software that everyone’s working on. GPUs do serve that market. As neural networks with millions of connections for image and voice processing, language, and so on make their way into smaller and smaller consumer devices the need for more GPUs or processors tailored to that software will hopefully result in something that can become a new component on a Raspberry Pi or Arduino board. Though there is the possibility that processing will remain an online service instead. EDIT: It turns out there is a GPU on the Raspberry Pi — see the comments below. That doesn’t mean all the above frameworks will make use of it though. For example, TensorFlow supports Nvidia CUDA cards only. But you can still use the GPU for your own custom neural network code. Various links are in the comments for that too.
There is already competition for GPUs from ASICs like the TPU and it’s possible we’ll see more of those, possibly ousting GPUs from neural networks altogether.
As for our new computer overlord, neural networks as a part of our daily life are here to stay this time, but the hype that is artificial general intelligence will likely quieten until someone makes significant breaktroughs only to explode onto the scene once again, but for real this time.
In the meantime, which neural network framework have you used and why? Or did you write your own? Are there any tools missing that you’d like to see? Let us know in the comments below.














Well, the Raspi already has a GPU, of course. So it’s no wonder someone (ab?)used it for running a NN: https://petewarden.com/2014/06/09/deep-learning-on-the-raspberry-pi/ (unfortunately, no source code seems to be available)
I didn’t expect that but it makes sense given how popular the Pi is in gaming.
Sadly, TensorFlow supports only Nvidia CUDA graphics cards.
Source code for the Deep Belief port is on Github at https://github.com/jetpacapp/DeepBeliefSDK/tree/master/RaspberryPiLibrary.
I use Deep Learning For Java (https://deeplearning4j.org/) to do this: https://www.youtube.com/watch?v=fa9AgQbow-o
I use Deep Learning For Java (https://deeplearning4j.org/) to do this: https://www.youtube.com/watch?v=fa9AgQbow-o and this:https://www.youtube.com/watch?v=2V63YBjovDU
It is possible to run code on the GPU of the raspberry pi, as well.
https://github.com/christinaa/rpi-open-firmware/tree/master
linux boots on the arm, but most of the hardware is still uninitialized, sadly. patches welcome!
Back in the day, I found Timothy Masters’ books to be most informative and pleasant to read – he’s that most unusual combination of a mathematician who can also write English – and C++.
He correctly predicted/diagnosed all the current complaints about NN’s back in the early 90’s, which are now being brought up due to failing to follow his advice and guidlines from “way back when”. Such as “don’t go too deep until you prove you need to” – we now have deep learning as the rage which is often fooled by the simplest noise. “Use high precision math to find the error gradient when it’s flat” – so now we have (in order to promote the often misused “deep doo doo, or um, learning”) reduced precision floats.
I just have to laugh, this is yet another case of the new guys being unaware of what went before, re-inventing the wheel (and of course, taking credit), and missing what has been learned already with great effort. Guess what – things still work the same as ever.
“Practical Neural Network Recipes in C++” ISBN 0-12-479040-2
The basics of MLFF neural nets, as well as Kohonen and others, with history, tips, and working code.
“Signal and Image Processing with Neural Networks, a C++ sourcebook” where Timothy extends NN theory to the complex number domain (also with source code). ISBN 0-471-04963-8
Both by Timothy Masters (who also has a web site, but links here take too long to post).
Now you *really* have it easy. The first book is actually fun to read…
Resubmitted with this change as wordpress login is hosed and thinks this is already posted, but it isn’t.
In my observation, it seems that making something up off the top of your head and running with it could be a reliable way to get some very nice book recommendations. If only there was an equally reliable way to find such material earlier in the process.
There is a YouTube channel called “Two Minute Papers”. He highlights a lot of NN stuff that is both fascinating and inspiring: https://www.youtube.com/watch?v=rAbhypxs1qQ
This one is a nice place to start, because it’s only one page long, and it have interactive examples in a webpage:
https://cloud.google.com/blog/big-data/2016/07/understanding-neural-networks-with-tensorflow-playground
It’s funny how things we perceive as new have been in development since long before most readers here were born. Us truly old geezers know that the 80s and 90s were actually the second resurgence of artificial neural networks. The first started with the invention of Perceptrons in the late 50s: https://en.wikipedia.org/wiki/Perceptron
The reason for the cycles:
1. A new generation comes up, reads about the past, and wonders “why didn’t they ever finish this? Must not have been good enough technology at the time…” begins work on it, starts a new fad.
2. New fad generates lots of new ideas, propels the science even further
3. Giant corporations buy up the Intellectual Property rights to those ideas, then quash them because they can’t be easily used to force mass wealth transfer while violating consumers dignity.
4. Innovators and inventors go broke and can no longer pay for food and shelter
5. ideas and motivation to the few survivors languish for a few years
6. Back to step one.
Also, YouTube channel DeepLearning.TV is a good channel for an overview:
https://www.youtube.com/channel/UC9OeZkIwhzfv-_Cb7fCikLQ
I wish more and more frameworks start supporting OpenCL which is supported by many vendors (GPU and CPU). CUDA is nVidia specific.
Thx, for this overview… !
It’s my pleasure. Thanks for making that cool walking robot that I mentioned and for releasing all the details of how you trained it!
The problem with neural networks is that we haven’t made the algorithms to convert their actions into code or vice versa. If you do this then neural networks will be an overnight sensation.
Cognimem doesnt even warrant a mention? http://www.cognimem.com/index.php
Their Asic based neural network chips are amazingly easy to work with.
Nice. I see we’ve talked about it before http://hackaday.com/2012/07/17/finger-recognition-on-the-kinect/.
It sounds like you’ve worked with them yourself. What have you made?
My first intro to electronics came from Radio Electronics Magazine. https://archive.org/details/radioelectronicsmagazine?&sort=-downloads&page=2 I did so many of my first electronics projects with that magazine. It was my HAD in the 80s.
TAB books had an “electronics book club” advertised in it. One of those $4.95 for your first 5 books then every month another book would show up that you could return if you didnt want it but youd end up paying for it because it was easier than returning….like the .99c cd clubs. Well one month in my package contained “Experiments in Artificial Neural Networks” by Edward Rietman 1988…I must admit that at 14 it was beyond my skillset or interest so I returned it. But thats the first time I had any exposure to the concept….for historical reference.
Another really great tool for Neural Networks analysis and training is the python based library sciKit-learn.
My first use of Neural networks software was with Scilabs ANN toolbox. https://atoms.scilab.org/toolboxes/ANN_Toolbox
It was the only accessible scientific tool capable of training neural networks at the time that was free. It worked great ! and helped me a lot in understanding how neural networks and the gradient descent algorithm worked.
For a moderately rigorous intro, I really like Bishop’s “Neural Networks for Pattern Recognition”. It’s a bit dated, but it covers the basics very well.
Most of the “convolutional neural net” and “deep learning” and so on is just tweaking the basic framework at the margins — pre-processing the data in a clever way or simplifying the transfer functions to make multi-layer networks easier to train, respectively. A good grasp of the basics lets you see through a lot of the buzzwords.
I like those “dated” sources. Often you’ll get detailed explanations for things that were new back then but won’t be explained anymore in current texts.
There’s not much “Earth-Shaking” going on with the topic of “Neural Networks” right now – it’s just plodding along as it always does. But the visibility of the subject is becoming more exposed/impressive due to advances in the increased processing power of consumer hand-held devices. Most of what you see today about Neural Networks is hype from technologically uneducated “Marketing/MBA” types trying to spy on you more as well as move more hardware in the process.
Remember the days of “Fuzzy Logic” when every home appliance maker touted this technology but implemented it very badly? The only thing that came out of the “Fuzzy Logic” craze was a treasure trove of frivolous Patents issued by the USPTO that are just waiting to be hoovered-up by corrupt young Patent-Troll Lawyers – once they read my comment of-course ;-)
N.B., This comment post is NOT meant to demean Engineers & Scientists doing REAL research in are Neural Networks. You people are Heros IMO.
Very nice overview. A friend and I wrote our own NN software for a High School CS project in the early 1990s… in Turbo Pascal. We used the Hinton article as a guide. We trained it to filter noise from simulated music (sine waves). It worked quite well.