We live in a world built on the back of enormous technological advances in processor technology, with rapid increases in computing power drastically transforming our way of life.
This was all made possible thanks to three key factors: The von Neumann architecture that the vast majority of processors are based on; Moore’s Law, which predicted the trend of increased transistor count, leading to more functionality on the chip at a lower cost; and Dennard scaling, laws on how to make those transistors smaller while their power density stays constant, allowing the transistors to be both faster and lower in power.
But the rapid growth made attainable by technology solutions and scaling is nearing an end. The death of Moore’s Law is often pronounced, as chip companies struggle to shrink transistors beyond the fundamental limits of how small they can go. Device scaling has slowed due to power and voltage considerations, as it becomes harder and harder to guarantee perfect functionality across billions of devices.
Then there’s the von Neumann bottleneck. The von Neumann architecture separates memory from the processor, so data must be sent back and forth between the two, as well as to long-term storage and peripheral devices. But as processor speeds increase, the time and energy spent transferring data has become problematic, leaving processors idle and capping their actual performance. This problem has become particularly acute in large deep learning neural networks, limiting the potential performance of artificial intelligence applications.
Yearning to move on from von Neumann’s grand designs of the 1940s, an ambitious effort is underway at IBM to build a processor designed for the deep learning age.
Using phase-change memory devices, the company hopes to develop analog hardware which performs a thousand times more efficiently than a conventional system, with in-memory computing on non-volatile memory finally solving the bottleneck challenge.
But this new concept brings its own set of complex technological hurdles yet to be overcome.
In a series of interviews over the past six months, IBM gave DCD a deep dive into its multi-year project underway at its labs in Zurich, Tokyo, Almaden, Albany and Yorktown.
This feature appeared on the cover of the July issue of DCD Magazine. Subscribe for free today.
Handling analog information

"There are many AI acceleration technologies that we're looking at in various states of maturity,” Bill Starke, IBM Distinguished Engineer, Power microprocessor development, told DCD. “This is the most exciting one I've seen in a long time.”
Phase-change memory (PCM) “was originally meant to be a memory element which just stores zeros and ones,” Starke said. “What was recognized, discovered, invented here was the fact that there's an analog physical thing underneath it,” which could be used for processing deep learning neural networks as well as for memory.
“For the price of a memory read, you're essentially doing a very complex matrix operation, which is the fundamental kernel in the middle of AI,” Starke said. “And that's a beautiful thing, I feel like nature is giving us a gift here.”
Exploiting the unique behavior of chalcogenide glass, phase-change memory can - as the name suggests - change its state. Chalcogenide glass has two distinct physical phases: a high conductance crystalline phase and a low conductance amorphous phase. Both phases coexist in the memory element. The conductance of the PCM element can be incrementally modulated by small electrical pulses that will change the amorphous region in the element.
The overall resistance is then determined by the size of the amorphous regions, with the atomic arrangement used to code information. “Therefore, instead of recording a 0 or 1 like in the digital world, it records the states as a continuum of values between the two - the analog world," IBM notes.
The company has been researching PCM for memory for more than a decade, but "started building experimental chips for AI applications in 2007-2008," Evangelos Eleftheriou, Zurich-based IBM Fellow, Neuromorphic & In-memory Computing, told DCD. "And we keep producing experimental chips - one of those is the Fusion chip, and we have more in the pipeline."
Training and inference
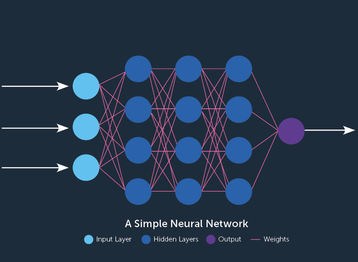
To comprehend how different chip architectures can impact deep learning workloads, we must first understand some of the basics of deep learning, training and inference.
Think of a deep learning neural network as a series of layers, starting from the data input and ending with the result. These layers are made up of groups of nodes that are connected with each other, loosely inspired by the concept of neurons in the brain. Each connection has an assigned strength or weight that defines how a node impacts the next layer of nodes.
During the training process the weights are determined by showing a large number of data, for instance images of cats and dogs, over and over again until the network remembers what it has seen.
The weights in the different layers, together with the network architecture, comprise the trained model that can then be used for classification purposes. It will be able to distinguish cats from dogs, giving a large weight to relevant features like whiskers, and will not be disturbed by irrelevant low-weight features like, for instance, clouds in the picture.
This training phase is a hugely complex and computationally intense process, in which the weights are constantly updated until the network has reached a desired classification accuracy - something that would be impractical to run every single time somebody wanted to identify a cat. That’s where inference comes in, which takes a trained model and solidifies it, running it in the field and no longer changing the weights.

The creation of the electronic brain
DCD reports on the epic decades-long quest to make computers more like the human brain
More work for less power
The long term aim, according to Jeff Burns, IBM Research’s director of AI Compute, is for PCM to be able to run both inference and training workloads.
"We see a very large advantage in overall compute efficiency," said Burns, who is also the director of the company’s upcoming AI Hardware Center in New York. "So that can be realized as: if you have a certain workload, doing that workload at much, much, much lower power consumption. Or, if you want to stay in a power envelope, doing a much larger amount of computation in the same power.
"These techniques will allow one of the most compute intensive parts of the computation to be done in linear time.”
By carefully tuning the PCM devices' conductance, analog stable states can be achieved, with neural network weights memorized in the physical phase configuration of these devices. By applying a voltage on a single PCM, a current equal to the product of voltage and conductance flows. IBM researchers Stefano Ambrogio and Wanki Kim explain: "Applying voltages on all the rows of the array causes the parallel summation of all the single products. In other words, Ohm’s Law and Kirchhoff’s Law enable fully parallel propagation through fully connected networks, strongly accelerating existent approaches based on CPUs and GPUs."
But this tantalizing promise of a superior technology that breaks free from the von Neumann bottleneck, that outlives Moore’s Law, and ushers in new deep learning advances, comes with its own set of issues.
"The problems are different in both inference and training," Wilfried Haensch, Distinguished IBM Research staff member, Analog AI technologies, told DCD.
Let's start with the comparatively easier inference space, and assume you still run training workloads on a GPU. "So, the trick here is, how do you get the weights from the GPU environment onto the analog array, so that you still have sufficient accuracy in the classification?” Haensch said.
"This sounds very easy if you look at it in a PowerPoint slide. But it's not. Because if you copy floating point numbers from one digital device to another, you maintain the accuracy - the only thing that you do is copy a string of zeros and ones.”

Analog accuracy issues
When copying a number from a digital environment into an analog environment, things become a little more complicated, Haensch said: “Now what you have to do is take the strings of zeros and ones, and imprint it into a physical quantity, like a resistance. But because resistance is just a physical quantity, you will never be able to copy the floating point number exactly. Physics is precise but not accurate, so you get a precise resistance, but it might not be the one that you want - perhaps it's a little bit off."
This inference accuracy issue is something IBM's Almaden lab hopes to overcome, running tests on long short-term memory (LSTM) networks, a complex deep learning approach fit for tasks with sequential correlation like speech or text recognition, where it can understand a whole sentence, rather than just a word.
In a paper presented at the VLSI Symposia this June, Inference of Long-Short Term Memory networks at software-equivalent accuracy using 2.5M analog Phase Change Memory devices, Almaden “deals with how to copy the weights into the neural network and maintain inference accuracy,” Haensch said.
The paper details how to use an algorithm that allowed researchers “to copy the weights accurately enough, so that we can maintain the classification accuracy, as expected from the floating point training,” Haensch said.
“So this is a very, very important point. Our philosophy is that we will first focus on inference applications, because they're a little bit easier to handle from a material perspective. But if we want to be successful with this, we have to find a way to bring the trained model into the analog array. And this is a significant step to show how this can be done.”
For inference PCM devices, IBM have “convinced themselves that this approach is feasible and that there is no fundamental roadblock in the way,” Haensch said. “For commercial use, inference is probably about five or six years away.”
Can analog devices do training?
After that comes training, with Haensch admitting that “the training part is a little bit out. You really have to re-engineer these non-volatile memory elements so that they have certain switching behavior.”
Over in the Zurich labs, researchers got to work on trying to overcome the inherent challenges with PCM devices for deep learning training.
“In deep learning training, there are basically three phases,” Zurich’s Eleftheriou told DCD. “There is a forward pass, that is similar to inferencing, in which you don't stress precision,” where you calculate the values of the output layers from the input data with given fixed weights, moving forward from the first layer to the last layer.
“Then there is a backward pass with errors, again you don't need high precision,” where computation is made from the last layer, backward to the first layer, again with fixed weights, he said.
The third part is where you “need to update the weights, thereby changing the connection strength between the input and output of each layer,” Eleftheriou said. It is this part that remains difficult, so the solution at Zurich is to run the first two phases of training - forward and backward passes - on the PCM. However, the weight updates are accumulated on a standard von Neumann processor before the updates are transferred rather sporadically to the PCM devices. “This is, in a nutshell, the whole idea."
Haensch said: “That's a very important stepping stone, because it allows us to create the ability to train without pushing the material properties too hard.”
Going commercial
Going beyond that stepping stone, as well as pushing towards commercialization, could have a profound impact on the future of deep learning, Haensch believes.
“If you look at the development of neural networks today, it is really driven by the properties of GPUs,” he said. “And GPUs require that you have narrow and deep networks for better learning - this is not necessarily the best solution. The analog arrays allow you to go back to shallow networks with wider layers, and this will open up the possibility to to re-architect deep learning for learning optimization, because you are not bound anymore by the memory limitations of the GPUs.”
Cindy Goldberg, program director of AI Hardware Research at IBM, concurred: “It’s about not just looking at the exact workloads of today, but how these AI workloads are evolving out of these very narrow applications into much more broad and evolving and dynamic AI workloads.
“This is what informs the development approach of these accelerators, it is not just about having the best widget of today that is out of date in six months, but about really anticipating how these workloads are evolving and changing for the long term.”


{kind=link}
{kind=link}
{kind=link}