
As the 2019 mushroom foraging season approaches it’s timely to combine my thirst for knowledge about low level machine learning (ML) with a popular pastime that we enjoy here where I live. Just for the record, I’m not an expert on ML, and I’m simply inviting readers to follow me back down some rabbit holes that I recently explored.
 But mushrooms, I do know a little bit about, so firstly, a bit about health and safety:
But mushrooms, I do know a little bit about, so firstly, a bit about health and safety:
- The app created should be used with extreme caution and results always confirmed by a fungus expert.
- Always test the fungus by initially only eating a very small piece and waiting for several hours to check there is no ill effect.
- Always wear gloves – It’s surprisingly easy to absorb toxins through fingers.
Since this is very much an introduction to ML, there won’t be too much terminology and the emphasis will be on having fun rather than going on a deep dive. The system that I stumbled upon is called XGBoost (XGB). One of the XGB demos is for binary classification, and the data was drawn from The Audubon Society Field Guide to North American Mushrooms. Binary means that the app spits out a probability of ‘yes’ or ‘no’ and in this case it tends to give about 95% probability that a common edible mushroom (Agaricus campestris) is actually edible. 
The app asks the user 22 questions about their specimen and collates the data inputted as a series of letters separated by commas. At the end of the questionnaire, this data line is written to a file called ‘fungusFile.data’ for further processing.
XGB can not accept letters as data so they have to be mapped into ‘classic LibSVM format’ which looks like this: ‘3:218’, for each letter. Next, this XGB friendly data is split into two parts for training a model and then subsequently testing that model.
Installing XGB is relatively easy compared to higher level deep learning systems and runs well on both Linux Ubuntu 16.04 and on a Raspberry Pi. I wrote the deployment app in bash so there should not be any additional software to install. Before getting any deeper into the ML side of things, I highly advise installing XGB, running the app, and having a bit of a play with it.
Training and testing is carried out by running bash runexp.sh in the terminal and it takes less than one second to process the 8124 lines of fungal data. At the end, bash spits out a set of statistics to represent the accuracy of the training and also attempts to ‘draw’ the decision tree that XGB has devised. If we have a quick look in directory ~/xgboost/demo/binary_classification, there should now be a 0002.model file in it ready for deployment with the questionnaire.
I was interested to explore the decision tree a bit further and look at the way XGB weighted different characteristics of the fungi. I eventually got some rough visualisations working on a Python based Jupyter Notebook script:
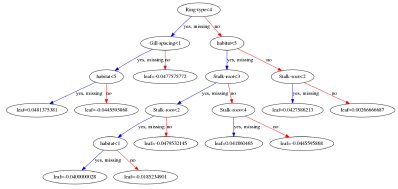
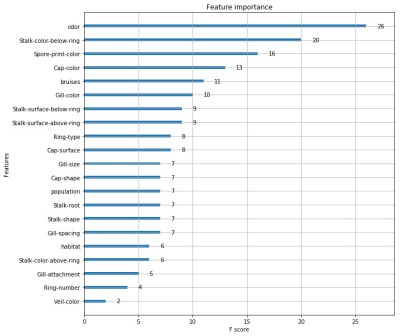
Obviously this app is not going to win any Kaggle competitions since the various parameters within the software need to be carefully tuned with the help of all the different software tools available. A good place to start is to tweak the maximum depth of the tree and the number or trees used. Depth = 4 and number = 4 seems to work well for this data. Other parameters include the feature importance type, for example: gain, weight, cover, total_gain or total_cover. These can be tuned using tools such as SHAP.
Finally, this app could easily be adapted to other questionnaire based systems such as diagnosing a particular disease, or deciding whether to buy a particular stock or share in the market place.
An even more basic introduction to ML goes into the baseline theory in a bit more detail – well worth a quick look.














Love your choice of mushroom for the picture :)
lol; bald head
If you can not trust it, it is not very useful. Mushroom identification is serous business. Some of the most deadly mushrooms are deadly in small doses, and make you mildly sick, but you recover, and than wake up dead a few days later. They grow all around where I live in North America. There are whole groups of mushrooms I avoid because a false identification can be fatal. My advice is if you want to enjoy mushroom forging, take a hands on class and learn the few of them that are both easy to identify and any lookalikes are just mild gastrointestinal irritants, not flat out poisonous. Most guides also suggest never eating wild mushrooms raw.
I would love to see an AI set up to help ID photos of mushrooms.
Sadly, I think it’s far too complex for AI photo ID. Part of the process involves smell, looking at habitat, digging up the root and making a paper print of the spores.
I was hoping the machine learning could predict where to find a patch of morels, based on previous sightings, local climate, and the like.
I have a day job, but this is a current project of mine. Happy to discuss collabs or any thoughts about training datasets…
PM sent :)
A professor of mine wanted to train a network on satellite images to find specific types of trees because his favourite mushroom would be a mycorrhiza partner of that type of tree.
But i don’t know if he ever did it.
I’m not your professor, but I’ve had this exact same idea I’m looking for hyper spectral satellite data of the United States (at least). I don’t know where to find an open source data set of this nature and I’m not sure how often or how sparsely it would be sampled.
I don’t mean this to sound harsh, but it’s obvious you aren’t an expert in this area, and have given some terrible advice. Saying that mushroom season is just now approaching shows you have a familiarity with only a specific set of mushrooms, yet you don’t state that. Saying to try a small piece of the mushroom to test for ill effects is ridiculous. I know you said to consult an expert first, but you either know for certain what it is, or you don’t. People are likely to only follow that advice when they don’t have an expert handy. Testing a piece of a deadly galerina can kill you.
To sum it up, either be intelligent and extremely knowledgeable about fungi, or be mushroom hunting with someone who is and who you trust your life to. Machine learning changes none of this.
https://www.woodlandtrust.org.uk/blog/2018/10/foraging-in-autumn-wild-mushrooms/:
“October is the season for wild mushroom hunting. The fruiting bodies of many species flourish in autumn with the return of the cooler, wetter weather.”
Seasonality chart: http://www.absolutelywild.co.uk/docs/chart-mushrooms.pdf
“wake up dead a few days later.”
Now that would be a hack!
The real question is where.
That would be a zombie.
You sound kind of paranoid. There’s more than 5000 types of mushrooms in North America only 8 are considered poisonous. That number includes the ones that wont kill you but will cause you to hallucinate. In the US most people who die are misidentifying a poisonous mushrooms which looks nearly identical to a safe mushroom from Asia. I challenge you to name a single person off the top of your head who died from a poisonous mushroom in the states. You might be overreacting.
All mushrooms are comestible … some only once.
Improper identification can, will, and does, result in deaths.
Humans do fail to make proper identification and this will never change, and this does results in deaths, hence clearly this subject and discussion is highly worthwhile.
Humans attempting to teach a machine will never reach 100% accuracy, the teaching process itself adds errors.
= this effort is simply adding to the number of failed identifications that will occur.
Humans make identification errors… humans make errors in teaching the machine. Humans eat the results… providing the final teaching step… but those that fail in this way do help improve the algorithms by removing themselves from the process.
I’ve clear childhood remembrance of when we moved out of the woods to the city, and though I loved morels and other mushrooms we would gather it was a relief to no longer be running the risk of Mom or Dad making an err.
I trust the computer. I do not trust the programmer. Where have you been?
but the machine can still learn from those failures, the person who ate them cant. with enough trial and error it’ll eventually reach a success rate far beyond what ppl can.
Only if it is actually aware you are dead (and it is to blame). ‘Oh would you kindly let the app know when it is in error.’ Really doesn’t work if you are dead, and nobody else knows the machine was wrong.
Might even become much more likely to misidentify the really really deadly ones as safe through lack of feedback – If they kill quickly enough there is no way to report it, and even if your cause of death is found will they know to tell the machine?
I also doubt it will ever reach a better success rate – as adversarial pattern recognition shows machine learning works in weird ways. Every camera is different the climate is changing so many variables that can and undoubtedly will mess with the accuracy. (About the only argument for Apples walled garden with massively overpriced hardware I can see is if folks rely on machine learned crap like this in the future – when millions of supposedly 100% identical devices with identical software are in the loop those devices should work well for machine learned models – not that I’d trust them with my life given any choice in the matter)
If you are going to forage either give yourself the Darwin award and save the poor machines the bother, or only eat that which is categorically impossible to be misidentified (and of course safe).
> this effort is simply adding to the number of failed identifications that will occur.
Wrong. The percentage of people who are stupid enough to trust unreliable methods for identification is fairly static.
….. we need volunteers for the testing.
I’ll try it, once.
Perhaps we could use lab mice? Or make the companies which make drug test strips (which invade the privacy of people) to make something more useful like mushroom test strips. e.g. A test for amanitine. Of course to be used directly on the mushroom before you eat it.
The test strips would be a good idea.
No, but you could easily adapt the app to do something like that. Getting the data might be more tricky though.
There are bold mushroom hunters. There are old mushroom hunters. There are no bold old mushroom hunters. This is bold indeed.
I’m guess, but seem like this is stand alone, individual thing, once it spits out a fatal error, then it’s learning is pretty much over. Who would pick up a death-machine off a corpse, and start using it, knowing it screwed up, and killed the previous owner? Now, if it was web connected, and was sharing what it learned, and learning from other peoples experiences… Wouldn’t is screw up frequently, if some of the end users were using the app for finding poisonous, or psychedelics? You train it from a book, but doesn’t learning go beyond the book? Seems it would cheap, easier, and probably more reliable, just to buy the book and look it up yourself. Isn’t the training, just to get it started, and it learns from there. If it’s taught bad things, it will do bad things afterward.
I seem to recall that Mathematica has a ML demo that does this. I think it used some 20 odd variables, and that’s not even getting into microscopic spore features or DNA analysis that some species identifications require.
It might be a useful tool for an experienced forager (several rungs down the ladder as it were) or a researcher, but I think it’d be down right dangerous in the hands of an inexperienced forager. And, damn it, Ganoderma tsugae is not Reishi, it’s closely related, but it’s not Reishi. Not get off my lawn kid. 9)
I’d sooner use this technology to hunt dandilions and other weeds in my lawn. Now that would be useful, no chemicals either. :-)
I keep hoping one day I’ll have enough free time to try building a robot that could wander around the yard and pick up dog poop, physically destroy weeds, or vacuum up fire ants. All the pieces seem to be lying around waiting to be put together for those kinds of targeted tasks.
I’m actually working with a startup in France that is doing exactly this right now. I think they’ll have a product sometime next year or something.
I’ve wondered about this same thing. Equip it with a small mechanical core-taker to take out a plug of dirt where the dandelion is. Let it roam around the lawn, doing its thing until all the dandelions have been removed. I’ve thought about capturing images for some machine learning/training sets, but like so many other projects, I only have so much time. :(
This message conversation is more interesting than the original article, lol
I don’t get why people are so sceptical.
There are many hacks and dangerous experiments out there. This is just one of them. Why does this one in particular trigger so many people?
Because it fits on a graph of reliability versus risk in a zone that firmly makes it useless. Buzzwording ML like this in situations which are guaranteed to disappoint is causing problems for AI research in general. This attitude that you can just sprinkle ML on a stack of GPUs to solve any problem has gotta go sooner or later.
I don’t mind if an AI project mistakes a tulip for a dandelion and snips it. Such an err with this AI project would snip part of your family tree.
I understand the concern with classification errors from an algorithm which whose mistakes could result in death. That being said, I think the design of a mushroom ID algorithm should NEVER output a single species classification, rather it should build uncertainty into the output. What is more, the OPs algorithm uses 22 observation details to come to a conclusion, which is a start, but adding a computer vision piece and location/weather contextualisation could help make the ID more robust.
Even when it is just humans IDing mushrooms, a vigorous and holistic approach that includes noting the environment, season, weather, lookalikes, etc. is required for any semblance of certainty in identification. Given the same inputs, a machine learning algorithm can only be as certain as the humans who ID the training data…
In the end, no algorithm alone could convince me of a mushroom’s ID, but it might put me onto the scent of something that I hadn’t thought of or known before. As long as the algorithm doesnt force me to eat what it deems to be potentially edible, I don’t mind a wrong conclusion.
I’d take it a step farther: rather than guess at what it is, I think it should output what the mushroom definitely isn’t. Better to tell you not to eat something edible than give you ok to scarf destroying angels or whatever.
Eating a common field mushroom will give 5% chance of death.
Great article, I wonder if building an app designed to scan only for target mushrooms and distinguish between their look alikes…like, is this a chanterelle? The user would need to have enough knowledge to scan only the ones that look like the target, otherwise too many scans would result in na results.
Yes the app could be refined to do this – it would be fairly easy to change it. Also, hard code info on the deadly mushroom species, region by region, alongside the machine learning stuff for extra safety.